Detecting targeted attacks
The 'Detect the Undetectable' paradox
The aim of this research article is to describe how organizations can detect threats, even when attack methods are used that are not yet known to the security industry and therefore suitable detection methods are lacking. It subsequently explains the importance of threat modeling, understanding the threat lifecycle and the role of cloud native SIEM technology and the MDR-provider in this.
Summary
To address the ‘detect the undetectable paradox’, this article will substantiate the importance of detection engineering and developing behavioral detection logic for organizations that may have to deal with sophisticated attacks.
This research article starts with describing managing the business risks of organizations and the role security monitoring plays in cyber risk management. To reduce your business risk as an organization, it is vital to understand your threat landscape and what this requires from your security monitoring solution in terms of detection data sources, detection logic and detection technology. To address the ‘detect the undetectable paradox’, this article will substantiate the importance of detection engineering and developing behavioral detection logic for organizations that may have to deal with sophisticated attacks. This concept on detection is demonstrated based on a case study and more specifically the SolarWinds attack that took place in 2020, as it is one of the most significant recent breaches.
The MITRE ATT&CK framework provides an important piece of the puzzle with regards to developing detection logic. By mapping out the threat landscape, you can translate this into a MITRE ATT&CK coverage map, to see where there is coverage from a detection logic perspective. However, MITRE ATT&CK comes with a blind spot as it is about the observed threats. So, what about the unknown threats? This is where the threat lifecycle comes into play, giving insight into the different stages a threat might be in and what this means for detecting it. In the end it will be difficult to detect something that is both unknown and where detection logic is lacking, yet it is vital to protect an organization against sophisticated targeted attacks. In other words, this is the “detect the undetectable paradox” faced by organizations with a high-risk profile.
In our partnership, both Chronicle and Hunt & Hackett play a quintessential role in detecting the undetectable:
- Cloud native SIEM technology — As a cloud native solution, Chronicle among others, provides the technology and the correlation engine to consume and analyze petabytes of security telemetry data to detect the known threats in the threat lifecycle, as well as retrospectively on the data retention to facilitate thorough threat hunting find out whether an unknown threat has been missed, as more information about the threat becomes available over time. Furthermore, it provides the means to consume threat intelligence to detect both known and unknown attacks, including leveraging Indicators of Compromise (IOC’s), Yara-L rules as well as behavioral detection models;
- SOC provider — There is wide variety of SOC providers, ranging from MSSPs who solely focus on ingesting IOC-feeds to specialized MDR- providers, such as Hunt & Hackett,that utilize their frontline expertise to develop (customized) detection logic to address the threat landscape of their customers and applying all the detection means to address both the known and unknown attacks. To choose the monitoring service that fits the needs of your organization, it is important to consider the severity of the threat landscape that the organization faces, in combination with the overall (risk) profile, type of critical assets and risk acceptance level. These factors ultimately determine the sophistication level of threat detection needed to safeguard the organization.
"Detection engineering is a set of practices and systems to deliver modern and effective threat detection. Done right, it can change security operations just as DevOps changed the stolid world of “IT management."
Anton Chuvakin
Head of Solutions Strategy
at Google Cloud Security
Risk exposure & threat monitoring
Cybersecurity is for the most part done by what is pragmatically and realistically preventable, by limiting the attack surface. The residual risk resulting from the preventive controls is mitigated largely with detect & respond measures in critical areas of the attack path. The latter requires a form of Security Operations which is typically performed by a Security Operations Center (SOC). To make the most of both, the prevention, detection & response measures need to be tightly aligned, while detection of blind spots need to be identified and continuously reduced, based on new insights on vulnerabilities, exploits and attacks methods as it would otherwise lead to higher than accepted risk levels. This is however not the norm today, nor is it easy to do. Nevertheless, it is essential to safeguard an organization from targeted attacks, in particular those with a specific threat profile.
While this research article is essentially about how to improve detection and response by identifying and removing blind spots, it is ultimately about how to reduce cybersecurity risks in challenging environments. Security monitoring works best when closely aligned with prevention and incident readiness measures as they jointly determine the resilience level against an organization’s threat landscape. The effectiveness of these combined measures ultimately determines the level of business risk. Organizations typically can do little about their threat landscape, but they can optimize their approach to improve risk management, as outlined in Figure 1.
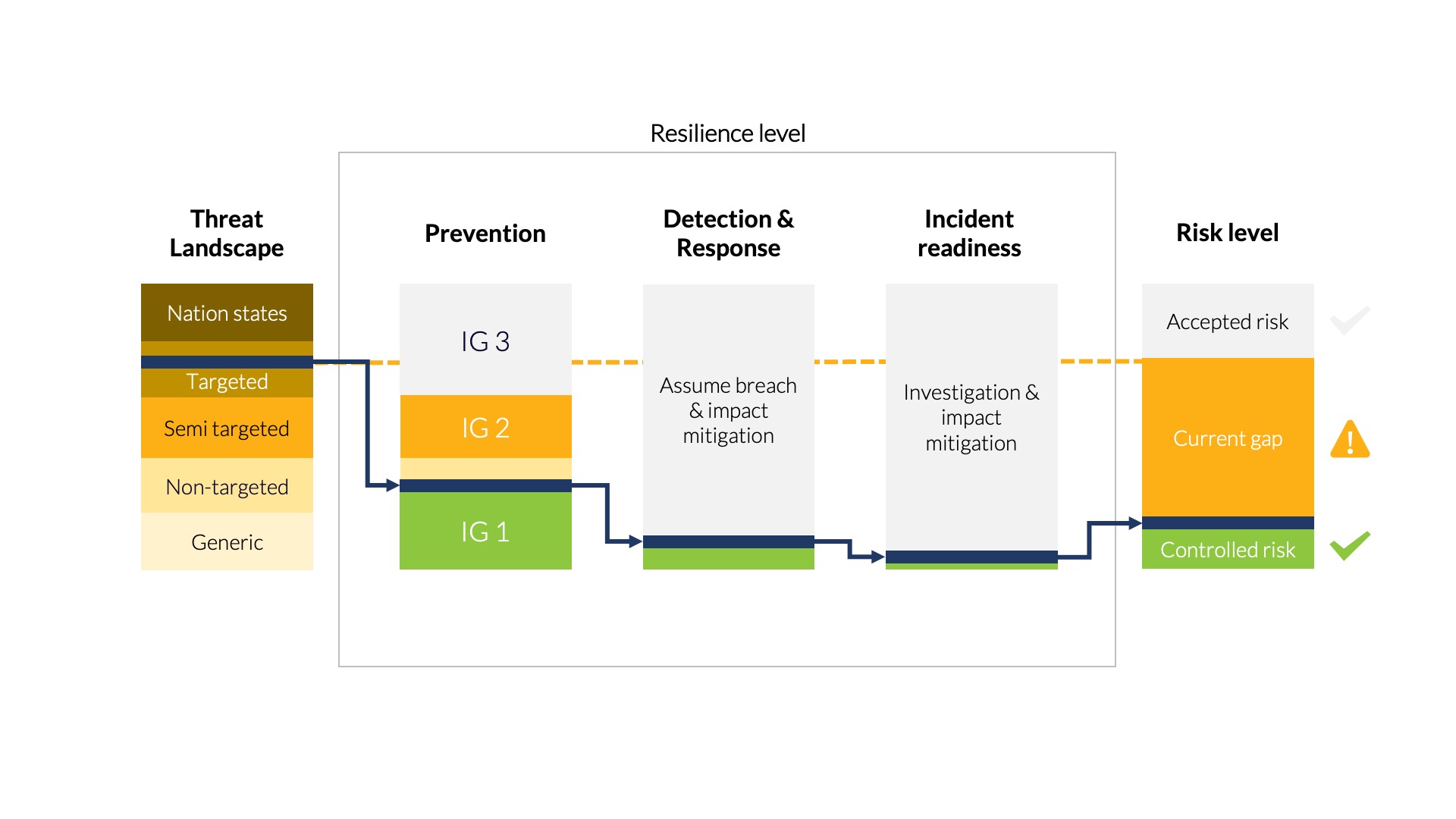
Figure 1 - Cyber security risks are managed through the combination of prevention, detection & response, and incident readiness controls.
The resilience level of an organization is determined by the level of prevention, detection & response, and incident readiness. When prevention measures are aligned with the threats an organization faces and are well implemented, it will lead to a small and manageable attack surface while also forcing attackers to take certain attack paths within the infrastructure to achieve their goals. Detection & response provides visibility on such critical attack paths and thereby offers a proactive defense whereby a successful initial compromise can be detected and mitigated quickly before it causes significant business impact. The final element is incident readiness, which ensures both technical and organizational readiness to provide incident response when an attack does escalate into a breach and/or crisis situations.
What determines the effectiveness of a SOC?
When setting up detection & response measures to improve resilience against the organizations threat landscape, there are four elements to consider that together determine the effectiveness of the project:
- 1Selecting data sources and detection logic to ensure relevant comprehensive threat coverage — Typically, when Security Operations Center (SOC) capabilities are built inhouse or selected from service providers, most of the attention goes to the technology selection, but the hard – and mostly overlooked - part is in selecting the data sources to monitor as well as determining what type of detection logic to apply on the data sources to ensure coverage of relevant threats. The latter is essential to understand the (limitations of the) monitoring capabilities of real-time detection of threats. Selecting data sources for collection is not only essential for threat monitoring, it also enables threat hunting when done right.
- 2Determining threat hunting capability needs — The second element is the ability to detect threats that may have happened in the past based on new insights. This is the domain of threat hunting, which today is almost seen as an alternative or replacement for real-time threat detection. While hunting for compromises on large sets of historical security data forms an essential part of modern detection, it is not a replacement for the real-time (inline) detection. The issue is that threat hunting offers unique possibilities to hunt for ‘unknown but detectable threats’ by searching for behavioral anomalies in security data, but today it is mostly used on ‘widely known and detectable threat information’ that emerges in the later stages of a threat lifecycle (see chapter threat lifecycles for more details). When organizations are potentially facing targeted attacks, they will need to detect threats earlier in their lifecycle which requires behavioral detection logic through both real-time detection as well as though retrospective threat hunts. In an ideal world, threat hunting acts as a feedback-loop to the real-time detection to identify detection blind spots and acts as an input to further develop and optimize detection logic.
- 3Choosing the detection technology that best supports the previous two elements — When the data sources and detection logic are determined to ensure relevant comprehensive threat coverage and the requirements for retrospective threat hunting, it will make technology selection much easier as the data sources, detection logic and hunting capabilities effectively form the requirements for the technology or security monitoring provider selection.
- 4Continuously identify and remove detection blind spots — While the previous factors are essentially prerequisites, the final key factor that determines the (technical) effectiveness of a SOC relates to the operational side and the ability of a SOC to improve the detection & response capability by continuously identifying and removing blind spots. Without this element the effectiveness of the SOC will deteriorate quickly. Yet, this factor has proven difficult to tackle as most organizations do not have visibility on potential blind spots and assume the continued enhancement through the intelligence feeds they consume as well as the updates they receive in the machine learning capabilities of the deployed technology.
The black box approach of most SOCs
In the past, the focus with SOCs was very much on the technology and intelligence feeds consumed. More coverage was mostly tackled by adding more intelligence feeds. These however consist mostly of relatively static information such as hashes, IP addresses and domain names, which in turn resulted in more false positives, but did not necessarily lead to more insight into the actual threat coverage.
More recently, technology providers promise detection enhancement through machine learning and artificial intelligence algorithms. However, this black-box approach to SOCs quickly leads to exuberance and over confidence on the ability to detect and respond to relevant cyber threats, while the more relevant threat intelligence data of network / host artifacts, tools and Techniques, Tactics and Procedures (TTPs) of the attackers still have limited to no visibility. To avoid over-confidence and therefore a greater risk exposure than anticipated, modern SOC projects should start with getting a solid understanding of the threat landscape that is relevant to the organization in question and translate this into the specific attack methods that need to be detected.
The alternative of a threat driven SOC
Most organizations struggle to align their SOC to their threat landscape, as this is not an easy thing to do. The difficulty with this approach is that the information about threat actors is fragmented and translating it into a structured process to determine the required data sources as well as the level of threat coverage and to identify potential gaps in detection logic remains both difficult as well as labor intensive. It does not help that the threat landscape for the most part is an elusive concept that is often abstract.
Threat landscapes are only recently being translated into an actionable (and universal) ‘language’, with the MITRE ATT&CK framework. The advantage of doing this is that the modus operandi of attack groups can be translated into (standardized) TTPs. From there it is possible to determine the security controls required to prevent such attacks, for example by using the Center of Internet Security (CIS) controls framework as a basis. This then provides a data driven foundation for making detection technology choices, sourcing intelligence feeds and for developing adequate (behavioral) detection logic.
By mapping the TTPs of the attackers in your threat landscape, you can determine which detection data sources, detection technology and detection logic is required to cover the threats relevant to your organization. How these three components will be embedded within your organization depends on your own threat model, threat landscape and your risk appetite. A thorough understanding of the threat actors you are facing, and the TTPs they use, makes it possible to determine which data sources are the most important to log and monitor. The MITRE ATT&CK framework helps linking these together as illustrated in Figure 2. To learn how threat modelling can be utilized see our blogs Threat Modelling as a starting point and Applied Threat Diagnostics.
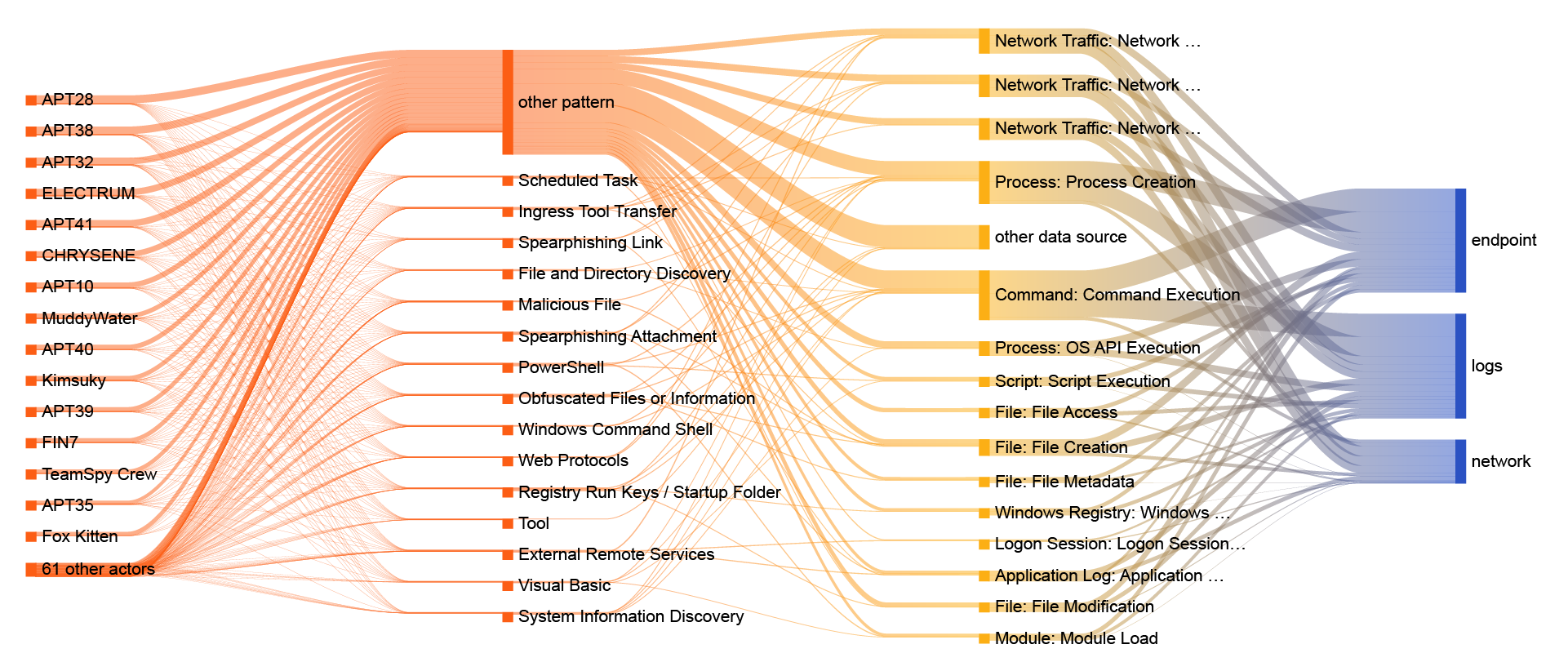
Figure 2 – Threat actor mapping to attack methods (TTPs), data sources and technology.
The more data sources and the higher the quality of the data sources covered by the detection technology, the more visibility you will gain, and the more TTPs you can detect on your assets. After all, every detection tool monitors a different scope and phases of an attack and ingests different data sources. Heatmapping the coverage of every piece of technology will give you directions on which detection technologies should have priority in your environment, and which detection technologies will help you to gain visibility over the full attack path.
However, the MITRE ATT&CK framework is about attacks that are known to have occurred and not about unknown attacks. For example, successful proof of concepts on novel attack methods are not included, as they have not (yet) been used to successfully attack an organization. Blind spots may therefore be introduced if one is solely focused on what is known by MITRE. It is also important to understand that every technique in the MITRE ATT&CK frameworks has not always been known to the greater public and was at one point probably unknown and undetectable. If MITRE focusses on what is known (‘Widely known & Detectable’ & ‘Known, but Undetectable’, the question is what are the techniques / threats that are unknown and how bad is it?
This question can be explored by plotting the level of threat awareness and knowledge of the underlying attack methods against the level of understanding in relation to threat coverage and detection logic. This approach leads to a threat visibility matrix as shown in Figure 3 to understand the level of visibility into a threat landscape.
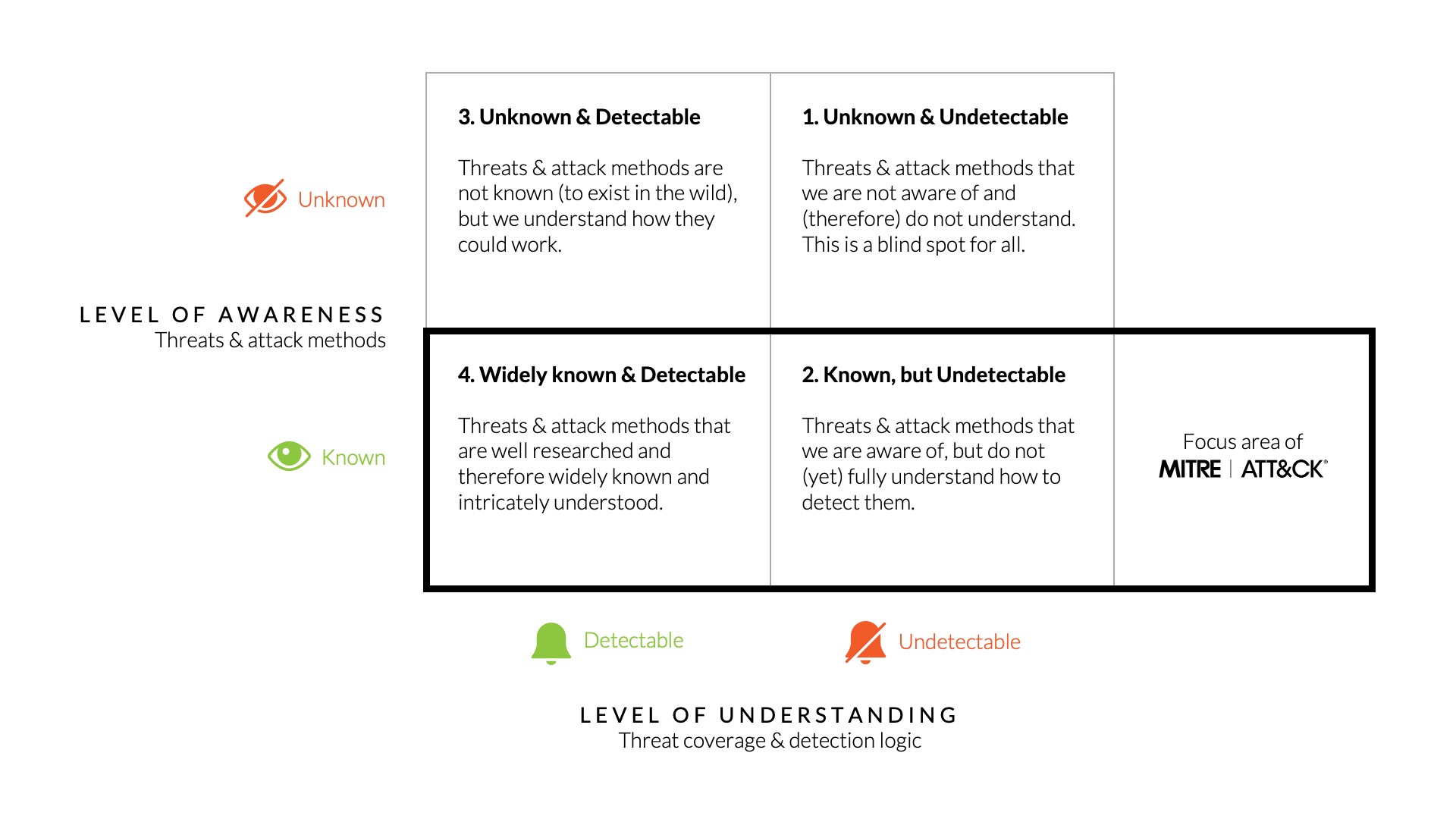
Figure 3 - Determining the level of visibility into the threat landscape.
The threat lifecycle
Threats also have a lifecycle of their own. Threats start out in the unknown (top) part of the. At that stage they are either ‘Unknown and Undetectable’ such as with nation state attacks or ‘Unknow, but Detectable’. In which category a threat falls depends on the knowledge and visibility the threat intelligence and security monitoring providers have on threats1 and could as such be provider specific.
Over time, threats evolve and become known and better understood, which means they evolve from unknown to the ‘Known, but Undetectable’ or ‘Widely known and Detectable’ categories. These are typically emerging and targeted attacks. With the passage of time most threats become ‘Widely known and Detectable’, also enabling attackers to use them. The upside is that at this point detection becomes widely available, through intelligence feeds or through embedded detection logic in technology as outlined in Figure 4.
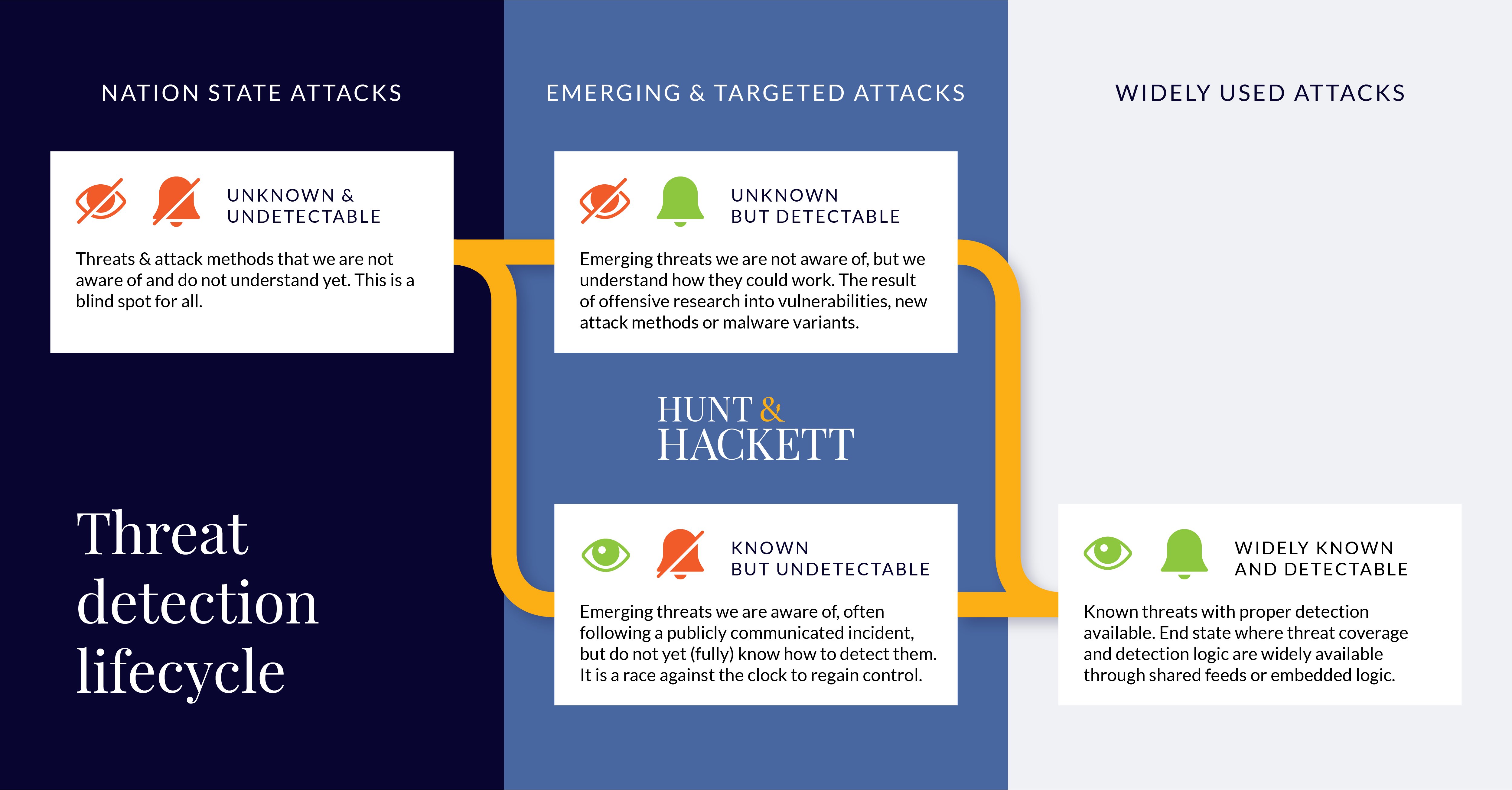
Figure 4 - The stages of the threat detection lifecycle.
When viewed from a threat lifecycle perspective, it becomes apparent where detection gaps may arise. The ‘Unknown and Undetectable’ threats are a blind spot for all, but over time they will – depending on the time, resources and effort spent – emerge in view of threat analysts within government agencies and specialized cyber security companies. At that point these threats and underlying attack methods are either ‘Unknown but Detectable’ or ‘Known but Undetectable’. It is also noteworthy that the former category is a blind spot to MITRE ATT&CK, as they are focused solely on known attacks that are observed in the field. The latter category was the case in the early phases of the Citrix, SolarWinds and Log4J vulnerabilities. This then starts a rat race to develop threat specific detection logic, so that potential exploits of the vulnerability can be detected.
This race to detection logic is necessary but also a reactive and threat specific. The ‘Unknown but Detectable’ category is therefore more preferrable. This is mostly achieved when behavioral detection is developed and tailored to the organization’s needs. In turn, this enables an organization to detect anomalies and fingerprints of attacker network/host infrastructure, or the tools or TTPs as indicators of an ongoing attack. This however requires advanced intelligence about the attack group's operating methods on the one hand and a clear understanding and baseline on normal behavior within the organization’s digital environment on the other. This is mostly the domain of specialized intelligence firms and intelligence driven MDR-firms. When organizations are confronted with a threat landscape with actor groups actively targeting similar organizations in the sector, it is advisable to work with such a specialized firm to develop tailored detection logic in accordance with the organizations threat landscape and specific digital environment.
Over time, when threats are better understood and detection logic becomes more widely available, it transitions into the ‘Widely known & Detectable’ category. This is also the lifecycle phase where most retrospective threat hunts are performed to look for traces of previously missed attacks. Threat knowledge is in this phase likely to be included into intelligence feeds and embedded into a variety of technology products, so for those organizations that deploy detection technology it is largely controllable. This is also where cloud native SIEMS such as Chronicle are relevant as they offer automated retrospective threat hunts on historic security telemetry data. Organizations that do not operate in a sector with a significant threat landscape or that do not have a profile that fits with targeted attacks, may, in combination with actively reducing the attack surface, rely on this form of detection typically offered by MSSPs.
However, when organizations are facing a threat landscape with attack groups actively targeting their sector, it is advisable to not solely rely on intelligence feeds, threat detection and hunting technologies that operate in the ‘Widely known & Detectable’ space. The attack techniques used for targeted attacks are often more sophisticated and make (significant) efforts to avoid detection. These organizations would do well to assess their detection coverage, in particular (behavioral) detection logic, tailored to their specific threat landscape. In other words, they could benefit from identifying their blind spots and investing in (customized) detection logic that deals with the ‘Unknown, yet Detectable’ threats.
So, what about the 'Unknown & Undetectable'?
How do we deal with the “detect the undetectable paradox” that organizations with a high-risk profile face? The ‘Unknown & Undetectable’ threats are certainly daunting, but not all is lost. Attack methods that are unknown are extremely uncomfortable and often used by (but not exclusive to) nation state actors that use sophisticated attack methods or zero-days for an initial compromise. However, looking more closely at the attack chain in its entirety, there is almost always a known attack method used somewhere in the attack. The unknown part is mostly limited to a specific phase of the attack, while the other phases of the attack typically use known and/or at least detectable TTPs to achieve their goals, as is illustrated in Figure 5.
So, while the initial compromise phase may utilize an innovative or sophisticated new approach to attack a target, designed to evade detection, the reality is that most of the other phases of the attack chain are likely to include at least several known or detectable elements. Specifically, when detection is focused on detecting the tools and TTPs of relevant APT’s in combination with the (behavioral) detection logic developed for the ‘Unknown, but Detectable’ category. This means that even nation-state attacks can to some extent be detected in one or several phases of an attack, which is also the reason visibility over all phases of an attack is highly recommendable.
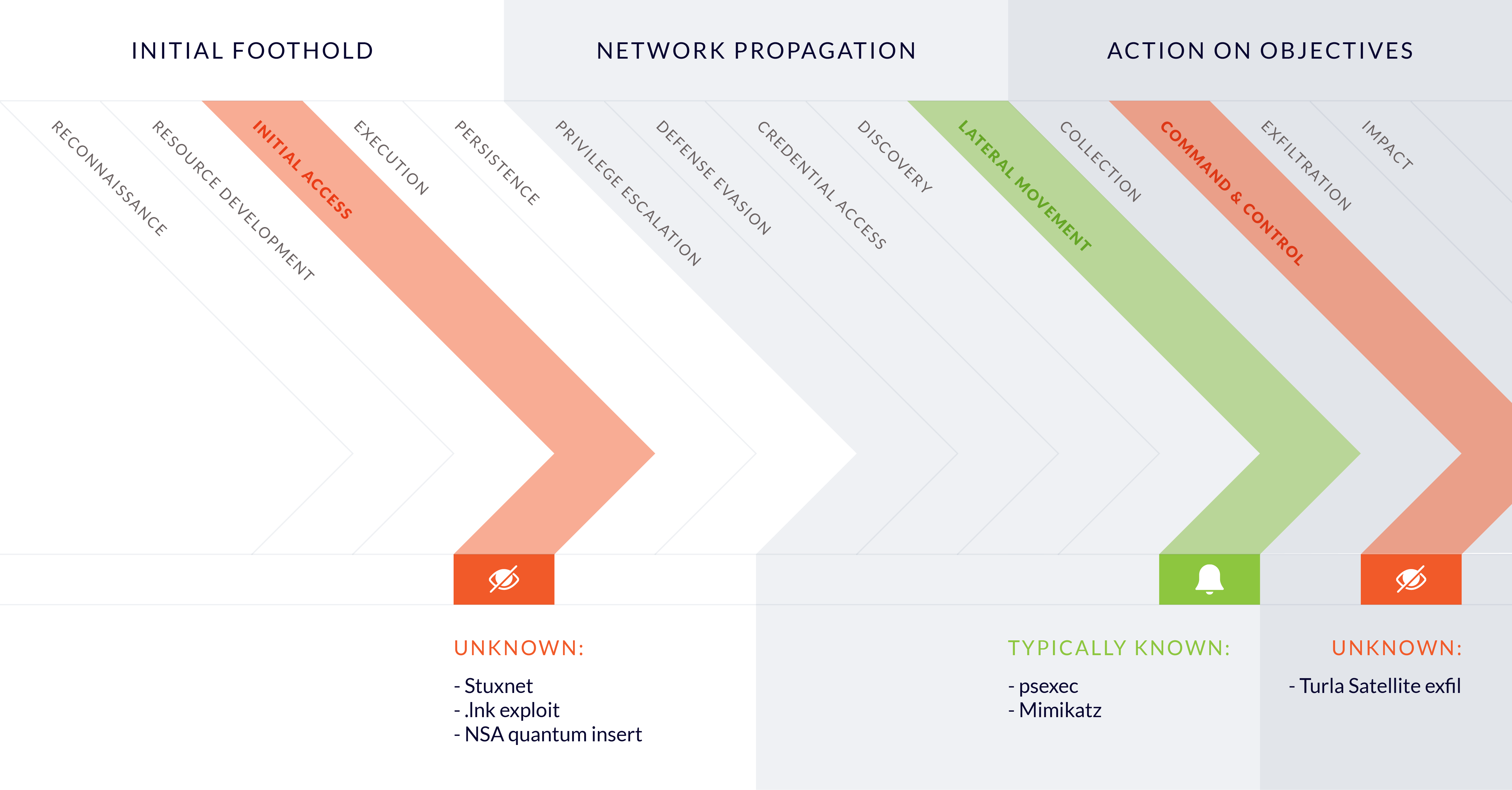
Figure 5 – Even novel attack methods are likely to include detectable attack elements.
Case study: The SolarWinds hack
To illustrate the blind spots in detection, let us examine the case of the SolarWinds hack in late 2020. In this attack, customers of the SolarWinds Orion product were targeted. The impact of the SolarWinds hack was major, because it triggered a much larger supply chain incident that affected thousands of organizations, including the US government effectively making it out to be one of the largest cybersecurity breaches of the 21st century.
The SolarWinds Orion IT monitoring and management software is designed for managing networks and IT infrastructure and is used by thousands of enterprises, IT-service providers, and government agencies worldwide. The system requires privileged access to the IT systems it managed to obtain log and system performance data. It is that privileged position in combination with its wide deployment that made SolarWinds a lucrative and attractive target.
In this hack, suspected nation-state hackers gained access to the software development pipeline and from there also to the networks, systems, and data of thousands of SolarWinds customers. As the software is used to managed IT-networks, the hackers also gained access to the data and networks of the customers and partners of the SolarWinds Orion tool, which resulted in the exponential growth of the number of effected organizations.
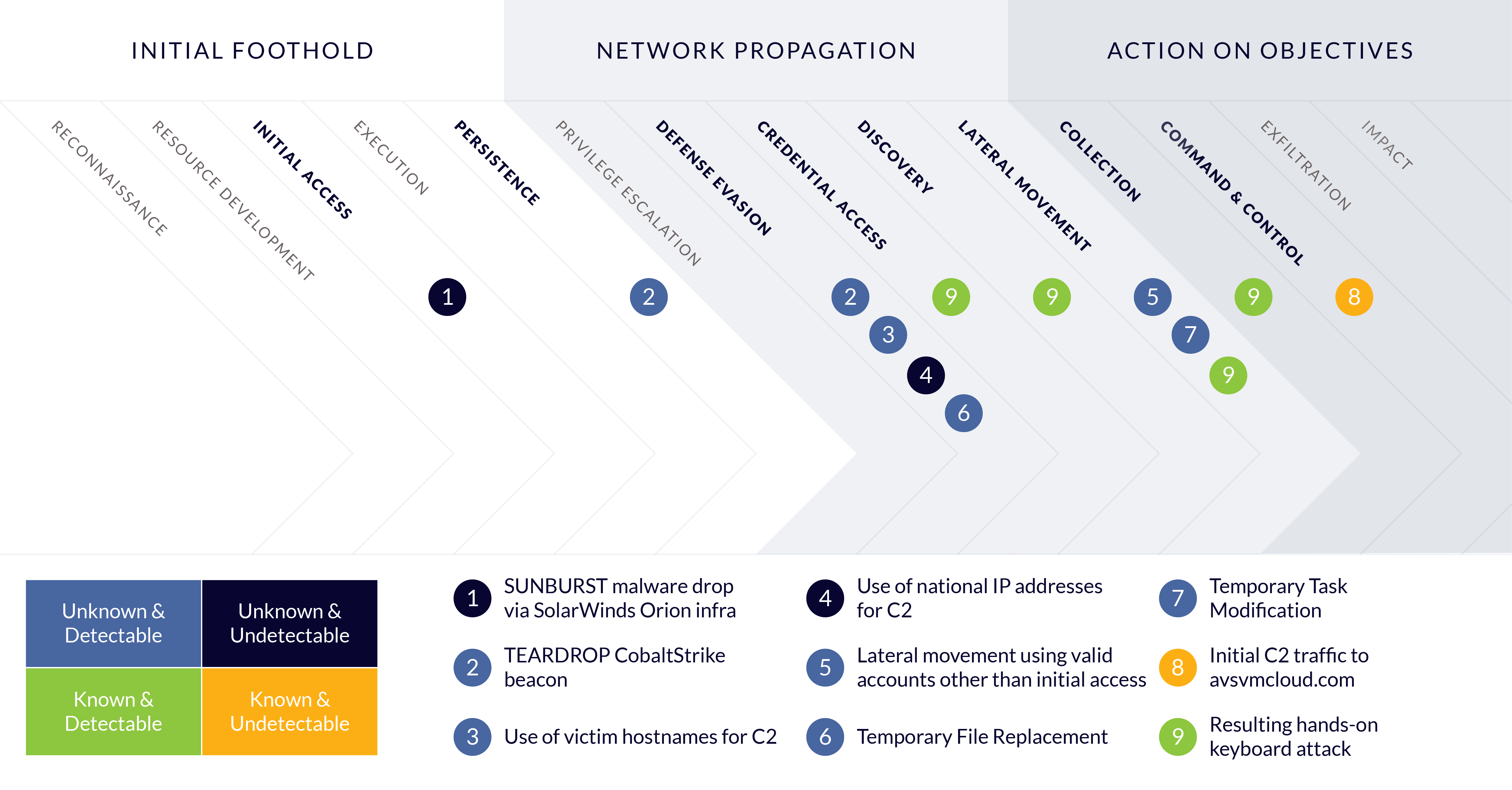
Figure 6 – Detection opportunities in the SolarWinds case, plotted on the MITRE ATT&CK tactics.
Most of the novel techniques used in the SolarWinds attack were early in the kill chain as can be seen in Figure 7. A significant part of the attack was novel an unknown at that time. The initial access(1) and defense evasion (4) fell into the ‘Unknow and Undetectable’ category, while a significant part of the attack techniques used in the early phases where ‘Unknown but Detectable’ (2,3,5,6,7). In the later phases of the attack several malicious techniques applied after initial access was similar to that of other attacks and where more ‘Widely Known and Detectable’ (9). Only the Command & Control techniques used in the attack where at that time ‘Known but Undetectable’ (8).
Each phase of the attack is outlined in detail in Table 1 and describes the type of detection that could then be used in to detect the TTPs at that point in time, as well as currently. The data in this table is based on the reports by Mandiant2, Microsoft 3and Volexity 4.
| Procedure | Technique | Tactic | Detection | Type of detection (day 0) |
Type of detection (now) |
|
|---|---|---|---|---|---|---|
| 1 | Drop SUNBURST malware using compromised supply chain of Solarwinds Orion by UNC2452/APT29. Malware was part of the Solarwinds updates and signed by Solarwinds certificate. | T1195.002: Compromise Software Supply Chain, T1553.002 Subvert Trust Controls: Code Signing | Initial access / Defense Evasion |
|
1. Unknown & Undetectable | YARA detection of binary artifacts widely available |
| 2 | Deploy Cobalt Strike beacon (TEARDROP) as a memory-only dropper. Runs as a service from the Windows directory | T1543.003: Create or Modify System Process: Windows Service | Persistence |
|
3. Unknown, but Detectable5 | TEARDROP network IDS rules widely available |
| 3 | Threat actor uses hostnames for C2 that match legitimate hostnames of the victim. | T1036: Masquerading | Defense Evasion |
|
3. Unknown, but Detectable | List of hostnames associated in the Solarwinds attack is now available |
| 4 | Threat actor uses IP-addresses for C2 that are in the same country as the victim. | T1036: Masquerading | Defense Evasion |
|
1. Unknown & Undetectable | List of IP-addresses associated in the Solarwinds attack is now available |
| 5 | Lateral Movement Using Different Credentials | T1078: Valid Accounts | Lateral Movement |
|
3. Unknown, but Detectable | - |
| 6 | Temporary File Replacement | T1070: Indicator Removal on Host | Defense Evasion |
|
3. Unknown, but Detectable | - |
| 7 | Temporary Task Modification | T1053.005 Scheduled Task | Execution |
|
3. Unknown, but Detectable | - |
| 8 | Initial C2 traffic | T1071.001: Application Layer Protocol: Web Protocols | Command & Control |
|
3. Unknown, but Detectable | Monitor use of avsvmcloud.com domain |
| 9 | Resulting hands-on-keyboard attack: the standard playbook of privilege escalation exploration, credential theft, and lateral movement. | - | - |
|
4. Known and detectable | - |
Table 1 – List of detection opportunities in the SolarWinds attack.
The initial access and defense evasion techniques were ‘Unknown & Undetectable’ at the time of the attack (1, 4). Yet most of the techniques that followed as part of the attack were in principle detectable even if they had not been previously observed (2, 3, 5, 6 and 7). During the SolarWinds investigation by the cyber security community, it became apparent that these previously unknown techniques where being used. Only one aspect of the attack (initial C2 traffic) was at that time ‘Known, but Undetectable’ (8).
When each of the attack phases are plotted on the detection visibility matrix as shown in Figure 7, it becomes apparent that many aspects of the attack where novel and unknown (upper part of the matrix), yet at the same time many aspects of the attack techniques were detectable (left side of the matrix).
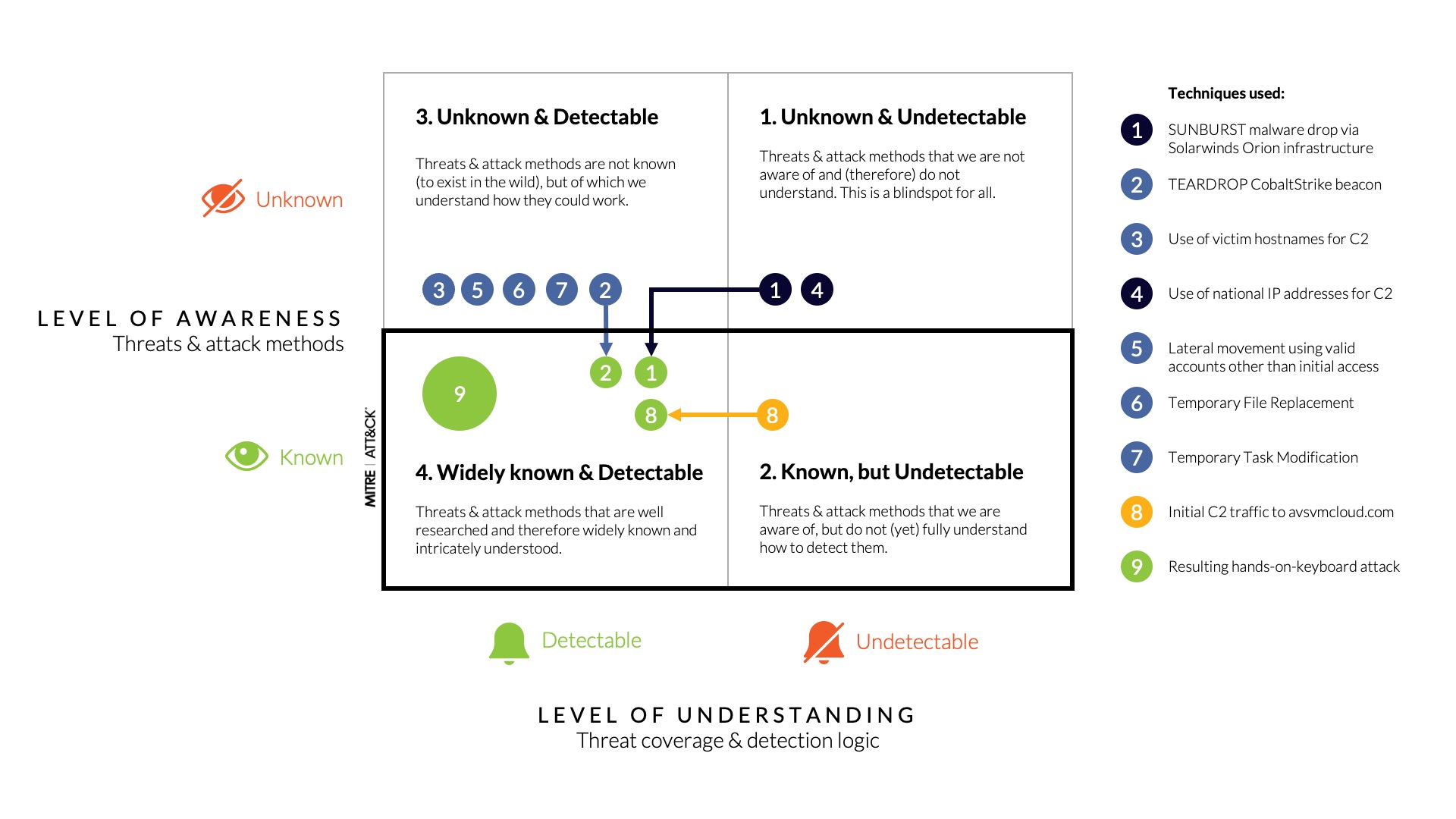
Figure 7 – Detection opportunities plotted on the detection visibility matrix.
As the techniques of the SolarWinds attack got better understood over time, detection against these techniques improved. Today the specifics to this attack are now widely known and detectable (1,2 and 8) by low-level IOCs.
To summarize, the SolarWinds attack consisted of nine TTPs, of which at the time of the attack itself (day 0) only the ‘hands on-keyboards attack’ procedure was within the focus of the MITRE ATT&CK framework and therefore ‘Widely Known & Detectable’. Five more elements where 'Unknown but Detectable'. These are relatively common elements of an attack that could have been detected if detection engineering was developed to deal with sophisticated attacks, in accordance with behavioral detection logic as described in chapter 4. As such, the impact of the SolarWinds attack on the US Government and other organizations could have been significantly less had this blind spot-based approach been followed.
How to apply this knowledge
To apply this knowledge in our Managed Detection and Response (MDR) proposition, we work closely with Google’s Chronicle for the heavy lifting data aggregation and security data processing. But also, for its behavioral detection capabilities and the flexibility it provides Hunt & Hackett to develop tailored detection logic to specific customer situations
Cloud native SIEM technology
Chronicle provides the technology and the correlation engine to consume and correlate all the important security telemetry data to detect the known threats in the threat lifecycle, as well as providing the data retention to facilitate thorough threat hunting in case we want to retroactively find out whether an unknown threat has previously been missed, as threats become known at a later point in time. Chronicle is specifically designed for security telemetry analysis and as it is a cloud native solution, it is designed to handle petabytes of data.
The Chronicle platform combines intelligence about global known threats, with behavioral threats inside the deployed network, and provides threat signals by means of IOC’s, Yara-L rules as well as behavioral detection models.
Chronicle provides automated IOC-matching with intelligence feeds and comes integrated with Google’s VirusTotal. This integration provides the SOC-analyst with contextual data to quickly understand what happens when malware is executed and to uncover relationships between the pieces involved. VirusTotal provides the behavioral signals from over a billion malware samples, to provide threat intelligence that is integrated in the workflow of the SOC-analysts. The IOC feeds and VirusTotal integration enable the platform to detect ‘Widely known & Detectable’ threats.
The Chronicle platform has adopted Yara as the basis for detection rule writing, but extended it to become Yara L, which enables operations to develop behavioral rules to detect suspicious and known malicious behavior. This form of rule development can be used for both the ‘Widely known & Detectable‘, and the ‘Unknown, but Detectable’ categories as it extends to behavioral threats inside the deployed network.
The Chronicle platform also comes with intelligence from Google Cloud Threat Intelligence, the threat research team within Google Cloud that enriches the Chronicle platform with global-scale threat intelligence. The team has a background with leading security organizations and focus on investigating malicious campaigns and deep diving into malware. The team leverages a wide variety of novel tools and techniques to detect emerging threats. It focuses not only on current trends and emerging treat indicators, but also on past and existing threats that may have gone unnoticed.
SOC-provider propositions
There is wide variety of SOC providers, ranging from MSSPs who solely focus on ingesting IOCs feeds to specialized MDR- providers, such as Hunt & Hackett with frontline security expertise, who build tailored MDR services for their customers, applying all detection means to address the known and unknown attacks. To choose the monitoring service that best fits the needs of your organization, it is important to consider the threat landscape your organization faces, in combination with the overall profile, type of critical assets and risk acceptance level. These factors ultimately determine the sophistication level of threat detection needed to safeguard the organization. The threat visibility matrix can also be applied for this purpose. The different types of security monitoring services available to organizations can be mapped in combination with the focus that they typically have, as illustrated in Figure 8.
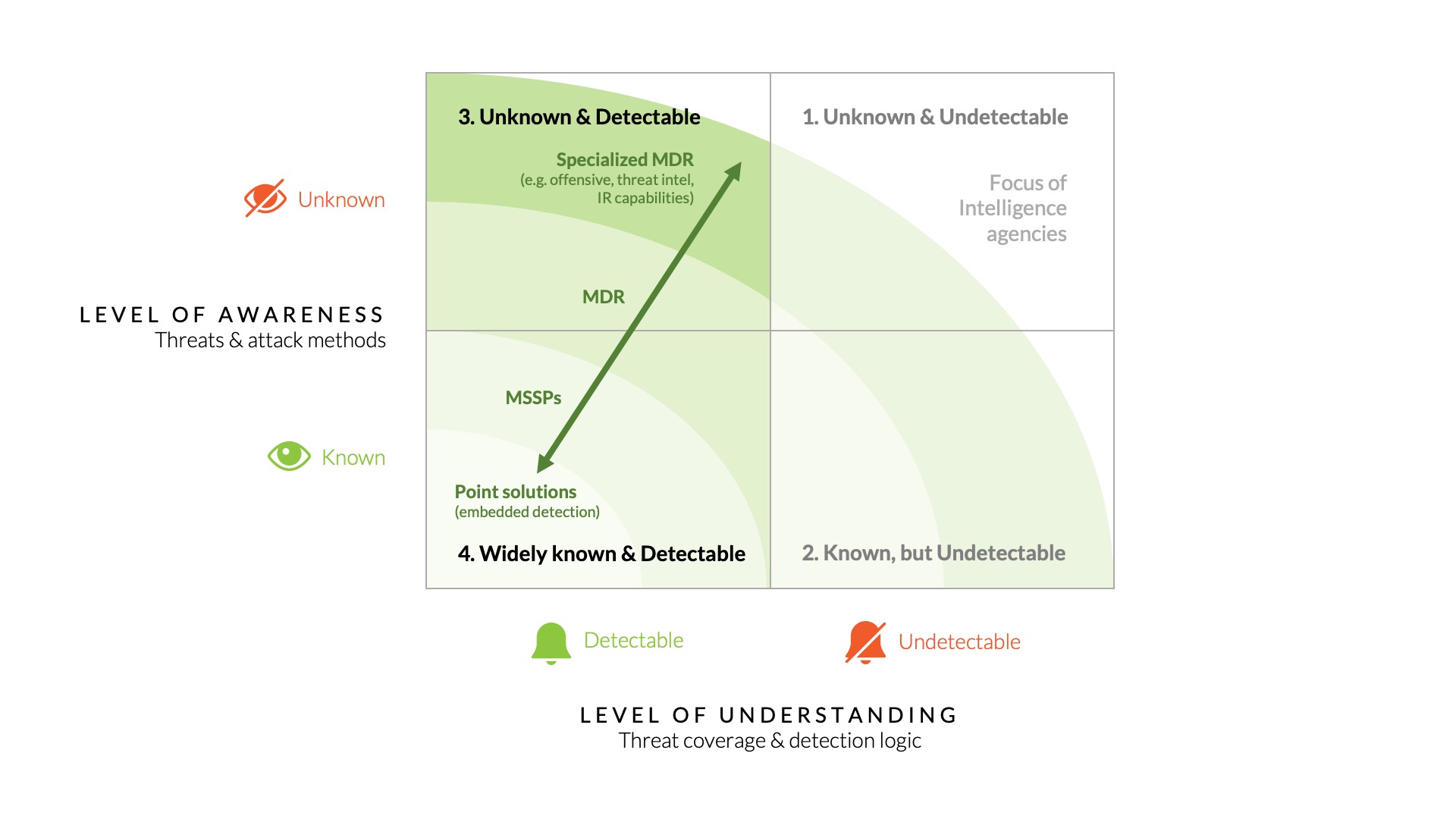
Figure 8 – Focus areas of the different types of security monitor providers.
Most security offerings from IT-providers are based on the embedded threat intelligence incorporated in IT and security products. MSSPs typically go beyond that and integrate these security products into one security architecture with a traditional tiered SOC-analyst model. While the latter offers more visibility and insight, both approaches are typically firmly planted in the ‘Widely known & Detectable’ categories of the threat lifecycle, which would have made the detection of the SolarWinds attack highly unlikely. These types of security monitoring are therefore less suited to organizations that face more severe threat landscapes and need to safeguard the organization against targeted attacks. These organizations are better off with more specialized MDR services.
Generally, MDR providers can be categorized by generic MDR providers, which typically are more focused on the (integration of) technology and often do not develop their own detection logic but consume open-source and paid intelligence feeds instead. This approach leaves the ‘Unknown, but Detectable’ category largely unaddressed and effectuates the detection of an attack as discussed in the SolarWinds case study unlikely. Generic MDR providers are typically providing a ‘standardized’ and therefore scalable solutions and cannot tailor or customize these to specific customer environments, such as threat detection for critical inhouse developed applications, therefore limiting themselves to the more generic IT environment.
The last category involves the specialized security companies that provide MDR services in addition to offensive, intelligence and/or Incident Response services. These MDR-providers typically operate in the trenches of cyberconflict and consciously develop knowledge and skills to improve their detection proposition. This category of MDR-providers typically develops their own detection logic on top of the open-source and paid intelligence feeds. They will typically also closely align their detection offering with prevention and incident readiness measures to raise resilience against an organization’s threat landscape. Typically, these MDR-providers can provide customized or tailored detection solutions which often includes customized applications, and even IoT and OT environments, and for which they develop tailored threat detection logic. The specialized MDR-firms consistently develop detection logic for the ‘Unknown, but Detectable’ category, particularly as new critical vulnerabilities or attack methods emerge. Following this logic of behavioral detection engineering, expeditious detection of an impending attack such as the SolarWinds hack becomes feasible or even probable. Furthermore, for those threat lifecycle stages where detection is not possible, the specialized MDR providers help those organization that must abate targeted attacks from a sophisticated adversary, to identify the prevention, detection & response security control gaps, to make sure that whatever cannot be detected is as much as possible prevented.
The Hunt & Hackett proposition
This research article offers guidance on how to detect targeted attacks by improving detection & response capabilities through identifying and removing blind spots. It also advocates that to reduce cybersecurity risks, security monitoring needs to be closely aligned with prevention and incident readiness measures as they jointly determine the resilience level against an organizations threat landscape. The effectiveness of these combined measures ultimately determines the level of business risk. This is however not the norm today, nor is it easy to do. Nevertheless, it is essential for organizations with a severe threat landscape to safeguard the organization from targeted attacks.
Hunt & Hackett provides a threat intelligence driven MDR service to its clients on top of Chronicle, complemented with an industry leading Security Orchestration, Automation & Response (SOAR) platform to offer active response. Hunt & Hackett leverages the detection capabilities of the Chronicle platform and enhances them with proprietary detection logic development to ensure that relevant ‘Unknown, but Detectable’ threats are covered in addition to the ‘Widely known & Detectable’ threats where active response is possible.
To protect organizations against ‘Known, but Undetectable’ threats, Hunt & Hackett integrates its security monitoring services with a threat modeling-based cybersecurity roadmap that includes comprehensive prevention measures based on the CIS controls, structured around different Implementation Groups. These implementation groups help organizations to apply prevention & response measures, where detection cannot be applied. Reducing the attack surface through prevention often has the beneficial effect that attackers need to use additional attack methods which in turn increases the chances of detection. Hence the importance of aligning detection with prevention and incident readiness measures.
Furthermore, the MDR-solution from Hunt & Hackett is technology agnostic to network, endpoint and cloud platform monitoring, and leverages investments that our clients have often already made in such technologies. When elements are still missing to provide visibility into the full attack path, solutions are recommended that have both the functionality and granularity to work optimally within our threat modelling based MDR-approach.
Contact us at info@huntandhackett.com if you want to know more about identifying and eliminating blind spots in detection and what we can do to help you control your cybersecurity risks.
![]()
Hunt & Hackett is a specialised Managed Service Provider (MDR) that is collaborating with Chronicle to provide intelligence driven cloud native security services for organisations to safeguard them against their organization specific threat landscape.

We live in a digital world, but the current economics of storing and processing enterprise security data have made it not only expensive, but difficult to safeguard against APT attacks. Organizations are looking to improve they ability to detect attack methods in a smarter, faster, and more cost-effective manner.
Chronicle is Google's cloud-based security telemetry platform capable of ingesting petabytes of data to quickly perform analytics and identify signals of threats at Google-speed through a predictable cost model based on number of users, not volume of data.
Questions or feedback?
