The techniques for concealing code execution became the favorite tool in Advanced Persistent Threat actor's arsenal because of the remarkable stealth benefits they can provide against conventional security mechanisms. Understanding how these techniques operate under the hood and having access to open-source proof-of-concept implementations that reproduce the corresponding behavior greatly helps with detection engineering and aids in incident response investigations.
The project we present here encompasses many months of dedicated research by diversenok_zero. It covers a wide range of concealed code execution techniques and investigates the related internal mechanisms that make them possible on Windows systems in the first place. The activities throughout this research included documenting the technique's functioning, preparing sample implementations, and observing their side effects.
The sample implementations we provide can serve as a testing toolkit that security engineers can use to challenge existing detection logic. These tools fall into two categories: code injection that attempts to mask additional payloads within legitimate running applications and process tampering that starts arbitrary programs while borrowing the identity of trusted components.
Furthermore, the third portion of the project focuses exclusively on discussing detection mechanisms that can identify the use of concealed code execution techniques. It gradually follows through three subsequent stages of detection: static, runtime, and forensic. The material offers various suggestions, provides YARA rules, and demonstrates successful detection using custom experimental tooling (also included).
In short, the following values are present throughout the research:
- The systematic approach: The repository includes more than just a collection of tools or links to external resources. Each subject receives a detailed explanation of the underlying concepts; each specific case gets classified into generic categories.
- Proof-of-concept tooling: The write-ups are accompanied by example projects in C that demonstrate the use of the described facilities in practice.
- Beginner to professional: You don't need to be a cybersecurity expert to understand the concepts we describe. Yet, even professionals in the corresponding domain should find the content valuable and educational because of the attention to detail and pitfalls.
You can find the code and the detailed explanations at our GitHub repository:
|
Section(s) |
Description |
Code available at: |
|
Process Tampering techniques exploit various intricate aspects of operating system's functioning to violate assumptions made by security software and conceal code execution on the scale of an entire process. The famous examples of such techniques include Process Hollowing, Process Doppelganging, Process Herpaderping, and more. |
https://github.com/huntandhackett/concealed_code_execution/tree/master/Tampering |
|
|
In the broader sense, code injection allows performing operations from the context of another component, typically without interfering with its functionality. Such techniques are interesting from the security perspective because they allow attackers to blend-in additional payloads within existing logic, making it harder to distinguish between them. In this write-up, we analyze the fundamental mechanisms used during code injection and try to understand the underlying decision-making that might accompany the development of future techniques. |
https://github.com/huntandhackett/concealed_code_execution/tree/master/Injection |
|
|
The techniques for concealing code execution discussed in the offensive parts of the project have a shared primary objective: they attempt to fool security software and bypass security policies. Identifying something that actively hides its presence can prove challenging due to the inherent limitations it imposes on the detection methods. Luckily for defenders, most evasion and concealment techniques share common flaws that allow hunting for their entire families. This section describes the following topics: static detection, runtime detection, and forensic detection. |
https://github.com/huntandhackett/concealed_code_execution/tree/master/Detection |
The primary focus of the research project was on making the nitty gritty details behind these techniques easy to understand & reproduce to enable more people to develop robust detections.
Process Tampering
Process Tampering is a set of techniques that exploit various intricate aspects of the operating system's functioning to violate assumptions made by security software and conceal code execution on the scale of an entire process. The famous examples of such techniques include Process Hollowing, Process Doppelgänging, Process Herpaderping, and more.
Understanding Necessary Concepts
Before diving into the technical details, let's familiarize ourselves with the main terms and concepts. First, we have programs - binary files that include the code and describe the dependencies it requires, such as the OS functions it needs to use. Secondly, we have processes, which represent running instances of applications. Despite commonly referring to them as running on the system, processes never execute any code; they are merely containers that encapsulate runtime resources such as the memory and references to actively used OS primitives. Code execution is the responsibility of one or more threads that belong to a process and share all its resources. Technically, it is also possible to have a process with no threads under some circumstances; we will see how it comes in handy for some techniques later.
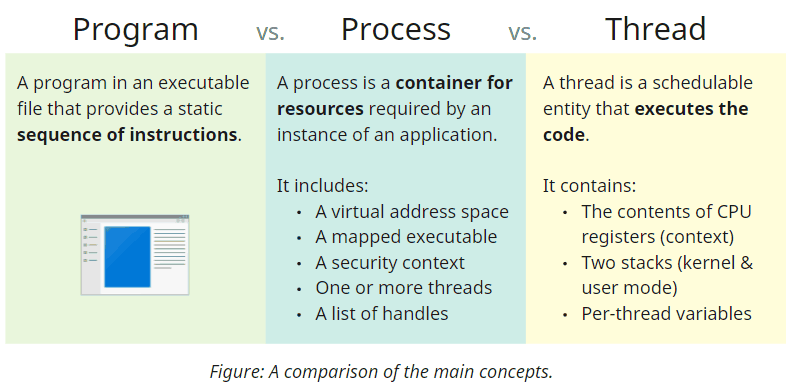
Every process includes a private virtual address space that encompasses all addressable memory. It contains regions with different memory protection (read/write/execute) and purposes (storing data or code). We will discuss the initial memory layout for newly created processes shortly.
How A Process Is Born
Windows includes multiple ways to start processes, ranging from high-level Shell API that only asks for a filename to low-level Native API that might require manually parsing the binary and creating the initial thread. But despite this diversity, everything boils down to two system calls.
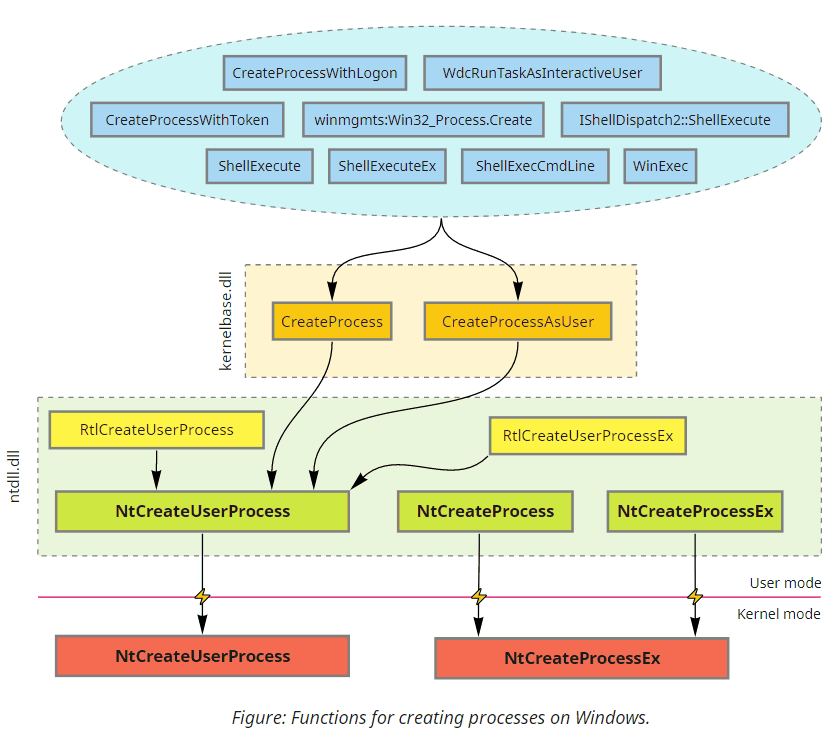
All officially documented functions eventually end up either in CreateProcess or CreateProcessAsUser. Some higher-level APIs call them directly; others require COM/RPC to forward the request to a dedicated OS component (such as AppInfo, WMI, Secondary Logon services, or even Windows Explorer) that invokes these functions on the caller's behalf.
While CreateProcess is quite a complex function by itself, most of the logic we are interested in is implemented inside the underlying NtCreateUserProcess syscall. Nonetheless, aside from relying on the Native API structures and being designed accordingly, NtCreateUserProcess is similar to CreateProcess. The function takes a filename, some parameters, and an array of attributes on input and produces a ready-to-run process with the initial thread created for us on output. Let's take a closer look at the main structures we can find in the address space of a newly created process:

Initially, every process has only two executable images mapped into its address space: the program itself and ntdll.dll (the base library that exposes Native API to user-mode code).
Technically, there is an exception to this rule: 32-bit applications running under WoW64 emulation on 64-bit systems additionally get a 32-bit ntdll.
Other dependencies (kernel32.dll, shell32.dll, etc.) get loaded later on demand by the initial thread when the module loader (implemented in ntdll) starts resolving the program's dependencies. Aside from the executable code, you will also find these several fundamental structures in every process:
PEB, or Process Environment Block is a memory region that stores and cross-references internal process-wide information, including process parameters, heaps, and the list of loaded modules.RTL_USER_PROCESS_PARAMETERS- a structure that controls the command-line arguments, environment variables, appearance settings, and other configuration options.CreateProcessconstructs most of its fields fromSTARTUPINFO, hence the similarity.TEB, or Thread Environment Block is another essential data structure that stores virtually all per-thread configuration. Several well-known functions likeGetCurrentProcessId,GetCurrentThreadId, andGetLastErrorretrieve information from the corresponding fields in TEB.- Thread Stack - a dedicated area for storing call hierarchy and local variables on a per-thread basis.
- Other structures that are less relevant for our discussion and, thus, not shown on the diagram - ApiSetMap, USER_SHARED_DATA, etc.
Processes created via NtCreateUserProcess (and, thus, CreateProcess, plus all higher-level functions) always include at least one thread. This thread will have a TEB and a stack somewhere within the address space.
Going Deeper
Process creation we've seen so far isn't inherently complex (from the programmer's perspective) because NtCreateUserProcess is a relatively recent addition introduced to simplify it. Before Windows Vista, however, CreateProcess used to rely on a different syscall - NtCreateProcessEx. This legacy function is still available in modern versions of Windows, so let's take a look at a small comparison of their functionality:
| Property | NtCreateUserProcess | NtCreateProcessEx |
|---|---|---|
| Means to specify the executable: | Filename (in NT format) | Handle to an image section |
Prepares RTL_USER_PROCESS_PARAMETERS? |
Yes | No |
| Creates the initial thread? | Yes | No |
| Immediately notifies drivers about process creation? | Yes | No |
The first and foremost difference between these syscalls is that NtCreateProcessEx does the bare minimum compared to NtCreateUserProcess. Not only does it create a process with no threads, but it also doesn't even allocate RTL_USER_PROCESS_PARAMETERS nor understand filenames.
As a result, dealing with this function is significantly more cumbersome because of all the additional operations it requires. Here is a rough recipe of how to re-implement the modern NtCreateUserProcess using the legacy NtCreateProcessEx:
-
Open the executable file for the new process.
NtCreateProcessExdoesn't understand filenames, so the first step in the preparation is to callNtOpenFile. -
Create an image section (aka file mapping) object from it. In terms of Native API, it requires calling
NtCreateSectionwith theSEC_IMAGEflag and the handle from the previous step. -
Create the process object using
NtCreateProcessEx. The new process will still get a mapped copy of the executable, ntdll, and PEB in its address space, but that's about it. -
Allocate and copy process parameters block into the target. The simplest way is to use the
RtlCreateProcessParametershelper locally and then transfer the resulting structure into the new process viaNtAllocateVirtualMemoryandNtWriteVirtualMemory. Remember that since process parameters contain pointers, they need to be adjusted correspondingly to be valid within the target. -
Adjust the corresponding process parameters pointer in the target's PEB using
NtWriteVirtualMemory. -
Map the section locally for parsing; determine its entry point address and stack parameters for the initial thread. It might be tempting to query
ProcessImageInformationviaNtQueryInformationProcessinstead, but, unfortunately, this approach does not account for mandatory ASLR under some conditions. The most reliable way is to manually parse the PE headers. -
Create the initial thread. Previously, this step would require manually preparing TEB and allocating the stack, but luckily, nowadays, we can let
NtCreateThreadExdo everything for us.
Anyway, as for the technical details, a carefully written implementation is always available for review in this repository. Still, you might wonder why anybody would use this overly-engineered approach. Here are a few key points:
- An explicit gap between opening and mapping the executable allows tampering with its content.
- The associated file for the image section can already seize from existence when we create the process.
- Security software that subscribes to synchronous process creation notifications only receives a heads-up during the creation of the initial thread. Thus, new processes with no threads are essentially invisible to security software.
Tampering With The Identity
Mechanisms that enforce security policy always need some contextual information about the caller. Windows kernel usually relies on access tokens in its security-related decision-making because these objects allow attributing activity to a particular user and determining their privileges. In some cases, however, various components also heavily depend on recognizing the identity of the process that attempts to perform a specific operation. For instance, per-application firewall rules and application control policies like AppLocker and Software Restriction Policies cannot function without the underlying mechanisms for process identification. But probably the most impactful example is anti-malware detection logic used by AV and EDR software, which often behaves differently based on the process to which it's applied. These differences can take a form ranging from as simple as explicit exceptions from the rules to reputation-based multipliers. Faking process identity can be a powerful tool in the hands of an attacker, allowing to defeat entire families of security mechanisms at once.
The Name Mismatch
The name and path to the executable are the primary pieces of identifying information about a process. The filenames are easy to work with; plus, knowing them allows further inspecting the application's files, computing hashes, verifying digital signatures, and much more. On the low level, however, the connection between the process and the file on the disk is not as straightforward as it might seem. There are several ways of retrieving the filename which might yield contradicting results. Some methods might provide outdated information, others can fail to query it after targeted tampering, and a few can even show arbitrary values of the attacker's choice. You can find a detailed overview of these methods in the detection write-up, where we will hunt for a mismatch between these values to uncover the use of process tampering.
Here are a few tricks and techniques that can introduce a name mismatch or otherwise confuse software that relies on retrieving filenames for processes, all without changing the content of the files:
-
Renaming. It might sound silly, but in some overly-simplified attack scenarios, it might be enough to rename the file before and after spawning the process from it. Of course, it won't fool security software that scans the executable synchronously with process creation, but it might circumvent mechanisms that check the filename later on demand. Such checks include looking up the short name from the process snapshot, querying the Native process image name, or reading it from the target's memory. Additionally to renaming, the attacker might also plant a different file under the previously used path, further increasing confusion when a human inspection is involved. Aside from using APIs that show outdated information, many tools (Task Manager, for example) cache filenames and, therefore, become unable to navigate to the correct executable after renaming.
-
Deleting. Deleting running executables is often considered impossible because the system locks files mapped into memory. There is, however, an edge case in the rules (discovered by Jonas Lyk) that allows doing so on NTFS volumes due to the logic behind alternative stream handling. While the system disallows deletion and modification of the locked primary stream, it doesn't prevent its renaming to an alternative stream. Because files must always have the primary (
::$DATA) stream, moving the content into an alternative stream creates an unlocked primary stream. Deleting this new stream, by definition, deletes the entire file and bypasses the lock on the alternative stream. At this point, every API that tracks renames starts returning errors because the active link between the process and the file is gone. The attacker might want to re-create the file and exploit the filename caching issues discussed above, but it won't restore the connection to the original process. -
Unlocking the executable. The previous item prevents security software from using rename-tracking APIs to locate the executable later during the process's lifetime, but it sacrifices the file we might want to keep. Instead of deleting it, we can duplicate the original stream, move the locked stream out of the way, delete it, and then replace the newly unlocked empty primary stream with the duplicate. As a result, the file effectively remains unchanged but becomes available for modification. Of course, the subsequent changes to the content do not affect the existing memory mappings that become disassociated from the underlying file. The functions that retrieve the identity of the process and track renames also start to fail for a similar reason. Note that this stream rotation trick is superior to deleting and re-creating the file because it preserves all of its attributes, the file ID, hard links, and other properties. The UnlockExe tool included with this repository implements this original technique.
-
Process Ghosting. The previous techniques might bypass some functions, but they fail to completely hide the filename because of the information that the system captures during process creation. Additionally, many security products opt-in to verifying the file synchronously, i.e., before we can tamper with its name. That's where the architectural decisions of
NtCreateProcesscome into play and benefit attackers. This syscall uses section objects (aka. memory mappings) which, as we know from the discussions above, can lose their association with the files on disk, effectively anonymizing it. When it happens, the system cannot query the name and establish the identity of the new process from the start of its existence, leading to some peculiar results. The most noticeable effect is the empty string that the system uses for the short image name in the process snapshot. Other identification methods either fail or return NULL. Notably, the caller still needs to provide some filename in theImagePathNamefield ofRTL_USER_PROCESS_PARAMETERS, but this string can point to an arbitrary file of choice.
The classical implementation of Process Ghosting works as follows: it creates a temporary file, marks it for pending deletion, creates an image section from it, closes the file (initiating deletion), and then creates a process from it. The demo provided with this repository follows the same logic. It is also possible to avoid using a temporary file and implement this technique utilizing the filename dissociation trick from the previous example (the UnlockExe demo); we leave this task as an exercise to the reader.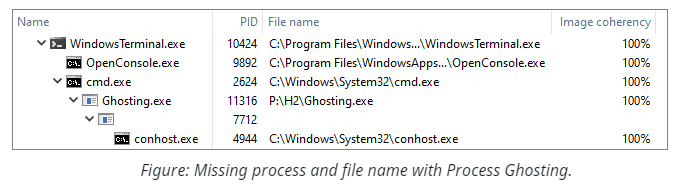
-
Process Hollowing. The process's identity is tight to the executable file used during its creation, not the content of the memory. And while there is a connection between those two concepts at the beginning of the process's lifetime, subsequent changes might invalidate this correlation. Process Hollowing exploits this subtle difference: it converts a trusted process into an empty husk and then uses it to execute a different binary. At the bare minimum, this technique spawns a new suspended process, maps the payload in its address space, adjusts the image base address in the Process Environment Block, changes the start address of the initial thread, and then resumes the target's execution. After the execution starts, the code in ntdll proceeds with the same initialization sequence as usual: it retrieves the image base address from PEB, resolves the imports for the module located there, and jumps to the provided entry point address. Because this type of tampering preserves the connection with the original file and happens after the system notifies the security software, products that don't inspect the memory (or at least its layout and properties) have a hard time detecting this technique. Due to its simplicity, the absence of file I/O, and small compatibility impact, Process Hollowing becomes a more formidable option than the previously discussed approaches. We cover this technique in the name mismatch category (and not the content mismatch discussed in the upcoming section) because it doesn't modify any files or code and always introduces a mismatch between the filename used during creation and the file mapped at the image base. Notably, existing implementations deviate in how they map the payload: using an image section that mimics the type of memory used for legitimate purposes or a private executable region where the attacker needs to copy the PE file according to its layout. The demo implementation provided with this repository uses the former approach, but keep in mind that both options are viable and have pros and cons.
The Content Mismatch
One of the core features in Windows that links memory management and file I/O is the ability to project files into an address space of a specific process. Aside from offering a remarkably convenient and optimized instrument for accessing data on the disk via mere memory operations, it also powers several other fundamental primitives, including the one that provides processes with most of their executable memory. Typically, Memory Manager keeps all file projections in sync with the backing storage. However, it also supports the copy-on-write semantics where multiple views derived from the same source can have different content because all modifications remain local. The images that process creation and DLL loading operations map into processes also utilize this mode, allowing them to combine the best of both worlds. Sharing memory by default drastically reduces its footprint, while making a private copy on any modification guarantees adequate isolation and sustains stability.
Having a private copy implies that the attacker that modifies mapped image memory doesn't leave any traces for security software that only looks into the files that stay untouched. However, such techniques generally fall into the category of code injection. What process tampering can offer is a bit more exotic because it originates from the opposite direction and describes what happens if we somehow manage to alter the underlying executable file. The answer might initially sound dull - the memory doesn't change, but it opens up the possibility of introducing content mismatch without ever modifying memory.
-
Process Doppelgänging. This technique uses an elegant approach that relies on the transactional filesystem (TxF). Transactions group I/O operations, providing a few convenient guarantees such as atomicity, consistency, isolation, and durability (see ACID). Because of the isolation, transactions effectively become a mechanism that allows a file to be in two states simultaneously. When we modify files in place, these two alternative views might share the filename and disagree on the content. This ambiguity also affects memory projections constructed from such files because they follow similar transactional isolation boundaries. In the end, that's what Process Doppelgänging does: it chooses an existing executable file, overwrites its content within a temporary transaction, prepares an image section from the transacted view (and, thus, containing the modified bytes), and creates a process from it. For the world outside of the transaction, the file remains untouched. Therefore, when a naïve security product observes the process creation event, it looks up the corresponding file, opens it outside the transaction, verifies the initial content, and doesn't raise the alarm. At the same time, the target's address space holds an altered version that merely hides inside the transaction under the same filename.
Interestingly, the original implementation rolls the transaction back immediately after creating the initial thread. This operation has a similar effect to deleting the underlying file since it disassociates the filename from the section object. Hence, it introduces artifacts that can give away the use of this technique to forensic detection tools. Of course, it happens after most anti-malware services inspect the process during its creation, but still. The demo provided with this repository supports the classical and a revisited approach that keeps the transaction alive for the entire process's lifetime. Comparing how these two alternatives behave against various detections is left as an exercise to the reader. -
Process Herpaderping. This relatively recent technique utilizes a simple yet effective alternative solution for achieving a file content mismatch. Because
NtCreateProcessrequires the caller to open the executable file manually, we can use this opportunity to request write access to the file - something that becomes impossible because of the locking rules once we create the section object. After obtaining this handle, we can backup the original file content and overwrite it with the payload. Then we prepare the image section (which reads and caches our payload) and restore the file's content to its original state. Despite the rollback, the section object remains using the payload data. Finally, we close the file and proceed with the typical low-level process creation (using the altered section object). Notably, because we never delete the file or revert transactions, the section (and, therefore, the process) never loses association with the original file. Even security products aware of Process Doppelgänging won't notice anything suspicious about the new process unless they perform a full comparison of the code in memory to the data on the disk. As with other techniques, you'll find the demo implementation in the corresponding folder.
Conclusion on Process Tampering
Concealing code execution on the scale of an entire process is an advanced approach for evading security software. Thus, detecting process tampering is a peculiar subject, notable for requiring specially designed tools that pay attention to detail. You can find more information on this topic in the corresponding section of the project.
Code Injection
[1]In the broader sense, code injection is a process that allows performing operations from the context of another component, typically without interfering with its functionality. Such techniques are interesting from the security perspective because they allow attackers to blend-in additional payloads within existing logic, making it harder to distinguish between them. In this write-up, we analyze the fundamental mechanisms used during code injection and try to understand the underlying decision-making that might accompany the development of future techniques.
The ability to inject code into running processes can be beneficial or essential, depending on the goals in mind. While a discussion of the reasons to perform code injection is out of the scope of the project, here are a few possible answers to this question:
- Debugging.
- Installing user-mode hooks.
- Subscribing to synchronous in-process callbacks such as thread creation and DLL load notifications.
- Bypassing per-process restrictions for specific operations. The operating system or security software can enforce constraints on calling various functions, limiting their use to particular processes. Firewall rules are one of the many examples of such restrictions.
Depending on the complexity of the task and other requirements, we might choose one of the two primary formats for hosting our code:
- Using shellcode provides a relatively stealthy way to execute code without leaving traces on the filesystem or even triggering detection. It can come in handy for installing simple hooks or issuing single function calls but doesn't scale well.
- Relying on Dynamic Link Libraries (DLLs) guarantees a simpler workflow for performing complex operations, including those that require bringing additional runtime dependencies. Injecting DLLs, however, usually leaves significantly more traces; we address this topic in the detection write-up.
Where Does The Code Come From?
To begin with, the processor needs a correct sequence of machine instructions available in the target address space before it can execute them. Before the era of Data Execution Prevention, processors were not distinguishing code from data, so as long as the bytes in memory had a valid interpretation as machine instructions, they were free to run. On modern systems, however, the memory protection model defines which regions are readable, writable, and executable, preventing attackers from redirecting execution into the data areas that might include untrusted input.
Thus, we have two options: either leverage existing code from the program itself or system libraries or allocate a new executable region. The second approach generally provides more flexibility, though, is significantly easier to detect.
Additionally, it can be challenging (if possible at all) to find a complete piece of code that achieves a specific non-trivial goal. There is, however, a family of advanced techniques that allow building an algorithm of any complexity given just a few simple sequences of instructions called gadgets. The most well-known are Return Oriented Programming (ROP) and Jump Oriented Programming (JOP). Notably, modern versions of Windows running on compatible hardware effectively prevent ROP and significantly complicate JOP, so we will not cover gadget-based techniques in this project.
Reusing Existing Code
Almost all programs depend at a minimum on several system libraries that expose Win32 API functions. To optimize memory usage, Windows utilizes a mechanism called KnownDLLs that includes a few dozen of the most frequently used built-in libraries and ensures that their memory is always shared. While their exact location is still randomized and does not persist between reboots, these libraries are mapped at the same base address across all processes. This fact drastically simplifies injection because when it comes to KnownDLLs, we don't need to resolve any remote addresses. But keep in mind that before using their code, we still need to verify that the target has the required DLL loaded.
It is also possible to use execution primitives from other modules readily available in the target's address space (including the primary executable itself). Unfortunately, they find limited use in general-purpose solutions because of the specificity and complications related to ASLR.
Another pitfall that might complicate reusing code is the calling convention and the number of expected parameters. As we will see below, there are several ways to gain execution that differ in the number of parameters they support. Unfortunately, they don't come even close to covering all possibilities. Hence, some circumstances might require writing a custom shellcode into the target merely to call an existing function.
Loading Shellcode
Writing executable code into another process isn't inherently problematic; you can find the overview of available options in the Managing Remote Memory section below. Preparing this code, however, is a substantially more complex task. Most of the time, it heavily depends on the concepts that are out of the scope of the paper. So, instead of talking about assembly and shellcode, we will focus on higher-level languages like C and, therefore, DLLs.
LoadLibrary - The Hybrid Approach
Probably the most widely targeted function during code injection is LoadLibrary. This function is implemented in kernelbase.dll and has an alias forwarder in kernel32.dll - two baseline libraries for all Win32 (both GUI and Console) applications. As a result, it is available in all Windows subsystem processes. Also, conveniently (as we will see below), it requires a single pointer parameter - the path to the file. The reason for the majority of injection techniques to target this function is simple: DLL loading is a local operation, i.e., there is no API for loading libraries remotely. Hence, most of the time, the sole purpose of a specific technique is to force another process into calling this function with the attacker-controlled parameter. There is, of course, a notable exception that allows avoiding this call altogether; we are going to examine this approach at the end of our discussion.
Hence, we can group all DLL injection techniques based on the primary API call:
LoadLibrary/LoadLibraryEx-based techniques.LdrLoadDll-based techniques.LdrLoadDllis a Native API function implemented in ntdll.dll that takes on the heavy lifting of module loading and powersLoadLibrary. UsingLdrLoadDllin place ofLoadLibrarycan be inconvenient due to its prototype but allows injecting DLLs into native-subsystem processes and might help avoid basic runtime detection.- Manual mapping techniques. These rely on an alternative path of, essentially, re-implementing
LoadLibraryusing memory manipulation routines. Writing a manual mapper is considerably trickier than other types of injectors because of the many nuances it requires taking into account when deploying the image into the target's address space.
Gaining Execution
Remote Threads
The simplest and most reliable way to start executing code in a different process is to create a remote thread. This operation requires PROCESS_CREATE_THREAD access (part of GENERIC_WRITE) to the target and is achieved via CreateRemoteThread, RtlCreateUserThread, or NtCreateThreadEx. The last function provides more control over the flags, which might come in handy for avoiding detection. For example, it can instruct the system to skip attaching to DLLs or hide the new thread from the debugger.
The payload is expected to follow the stdcall convention, take a single pointer-size parameter, and return a 32-bit value. The result value becomes the exit status and can be inspected afterward. Additionally, it is easy to synchronize with the code running on a new thread because the object becomes signaled upon termination. Some variations for the prototypes are naturally possible when targeting specific processor architectures, such as having no parameters or returning a 64-bit value on x64 systems due to binary compatibility. Remarkably conveniently, LoadLibrary closely follows this prototype, which allows us to invoke it directly without any stub code. As we will see below, the most basic DLL injection techniques rely on this exact approach.
The APC Queue
An alternative solution is to run the payload on the existing threads. There are many ways to hijack execution and achieve our goals, but probably the most convenient is Asynchronous Procedure Calls (APCs). APCs are a facility provided out-of-the-box by the OS. Essentially, it includes a per-thread queue of callbacks to execute when the thread is not doing any other work. Queueing new tasks is possible between process boundaries and requires THREAD_SET_CONTEXT access (which is, again, part of the GENERIC_WRITE mask).
One notable difference APCs have with new threads is a more flexible prototype for the callback function. It might sound surprising if you already have experience with the Win32 API wrapper (QueueUserApc) since it uses a prototype that is effectively equivalent to the one we've seen before. Nevertheless, the underlying syscall (NtQueueApcThreadEx) works slightly differently. The callback it uses follows the stdcall convention, has no return value, and takes three pointer-size parameters. Yet again, functions with up to three parameters and a return value should work due to binary compatibility on x64. This gives APCs an unparalleled advantage because it supports a significantly broader range of payloads. As for the disadvantages, the code that posts tasks to the queue cannot wait for its completion and determine whether the invocation was successful or not.
Additionally, there remains a question of when the payload will execute. Historically, until the recent versions of the OS, Windows exposed a single type of user-mode APCs that requires an explicit acknowledgment from the program, indicating that it's safe to run the pending calls from the queue. This approach is advantageous for preventing deadlocks as it helps to ensure that APCs do not execute while the thread is holding locks on synchronization primitives.
There are two ways for a thread to execute normal APCs: either sleep or wait in an alertable state or call NtTestAlert. Therefore, most of the existing implementations for APC-based injection take an indefinite amount of time before the payload executes. They work best against UI applications because those tend to wait for window messages in an alertable state.
Windows 10 RS5, however, added a new type of user-mode APCs called special APCs. Overall, they work similarly to the standard counterpart we just discussed, except they execute immediately (i.e., on the closest subsequent transition from the kernel to the user mode, before any application code). That makes special APCs incredibly useful for code injection. But keep in mind that the payload might get executed at an inconvenient time (such as when the thread is holding some locks), so, preferably, it should be as simple as possible. Technically, LoadLibrary doesn't satisfy this criterion, but, generally, it works well. The proof-of-concept code provided with this repository makes use of special APCs whenever possible.
Hijacking Execution
Here are a few alternative techniques that we will not cover in detail:
- Modifying thread contexts. The system maintains a snapshot of all registers that define the current state of every thread on the system. Two functions -
GetThreadContextandSetThreadContext(and their native counterparts) provide access to this information and allow arbitrarily changing it. Hijacking execution via modifying contexts requires theTHREAD_SET_CONTEXTaccess and a specially designed stub code (written in assembly) to be available in the target's address space. This stub prepares the stack, invokes the payload, and then restores the context to its original state. - Patching existing code or jump tables. There are a lot of varieties for this technique that target both specific applications and commonly used system functions from user-mode libraries. This diversity boils down to either changing pointers (such as patching the IAT table) or modifying machine instructions in memory. We will cover memory management API in the next section from the perspective of delivery, but keep in mind that the same API can be used for gaining code execution via patching.
- Installing the instrumentation callback. This per-process callback acts somewhat like a persistent special APC in the sense that it gets invoked on kernel-to-user mode transitions, but this time, repeatedly. This feature makes a powerful tool for gaining execution before any application-defined code has a chance to run. As with context-based injection, using the instrumentation callback requires writing a highly architecture-specific stub in assembly.
Delivering Data & Code
Managing Remote Memory
Processes on Windows use private virtual address space. Consequently, the code that runs in their context can directly access and modify only its own memory. This mechanism provides isolation that is essential for the stability of the OS and its components but might become inconvenient during inter-process operations. The functions we want to invoke remotely might require some context information, like the filename string for LoadLibrary, which should be accessible in the target's address space. Additionally, writing machine instructions requires keeping in mind various types of memory protection (i.e., the distinction between readable, writable, and executable pages).
To address the issues that arise from similar tasks (usually performed by debuggers), Windows provides various functions that allow manipulating an address space of a different process. These functions are, of course, subject to access checks but, provided sufficient permissions, can do effectively everything a process can do to itself.
| Function | Type of Memory | Required Access | Description |
|---|---|---|---|
| ReadProcessMemory / NtReadVirtualMemory | Any | PROCESS_VM_READ |
Reads bytes from an address space of a process. |
| WriteProcessMemory / NtWriteVirtualMemory | Any | PROCESS_VM_WRITE |
Writes bytes into an address space of a process. |
| VirtualProtectEx / NtProtectVirtualMemory | Any | PROCESS_VM_OPERATION |
Adjusts memory protection of an existing region. |
| VirtualQueryEx / NtQueryVirtualMemory | Any | PROCESS_QUERY_LIMITED_INFORMATION or PROCESS_QUERY_INFORMATION |
Retrieves various information about the entire address space or its specific region. Note that the Win32 function exposes only a small portion of the available properties. |
| VirtualAllocEx / NtAllocateVirtualMemory | Private | PROCESS_VM_OPERATION |
Allocates or reserves private memory. |
| VirtualFreeEx / NtFreeVirtualMemory | Private | PROCESS_VM_OPERATION |
Releases previously allocated private memory. |
| MapViewOfFile2 / NtMapViewOfSection | Shared | PROCESS_VM_OPERATION |
Maps a shared memory region (a section object in Native API terms) into an address space of a process. The memory can be backed by a paging file, a regular file, or an executable image. |
| UnmapViewOfFile2 / NtUnmapViewOfSection | Shared | PROCESS_VM_OPERATION |
Unmaps a shared memory region. |
Windows supports two types of memory that use a slightly different set of functions for managing but are otherwise interchangeable: private and shared (also called mapped). Mapped memory can work in several modes, including projecting files from the disk for reading/writing and images for executions. We will cover the difference when talking about manually mapping DLLs later. Thus, when allocating general-purpose memory remotely, we effectively have two similar options that require slightly different access to the target. The example projects in the repository demonstrate both approaches, allowing us to test how they hold against detection. Occasionally, it might also be possible to reuse and modify existing memory regions (such as PEB) for a more concealed allocation. Although, this approach is less generic because it depends on the existing memory layout that we need to inspect first. The most notable examples revolve around hiding new code in RWX regions created by Just-In-Time compilation.
You won't find many injection techniques that rely on shared memory because mapping it remotely was not exposed in Win32 API until Windows 10 RS2; although, it existed in Native API from Windows 2000.
Alternative Means of Delivery
Additionally, you can find various code injection techniques that use other means of delivering data into the target process, not covered here:
- Using the shared desktop heap. UI applications running on the same desktop share a memory region that the graphical subsystem uses to store the window-related state. Despite being mapped as read-only, various functions like
SetWindowLongPtrcan effectively write custom data into it. Provided we know the offset where our data landed (that we can obtain by scanning the region locally) and the address at which the buffer is mapped in the target process, we can compute a pointer that is valid remotely. Techniques like PowerLoader use this approach combined with ROP, but it can also serve as a means for regular data delivery. - Using non-memory storage, such as the Atom table. This table stores strings matched with 16-bit identifiers and managed via UI-related functions like
RegisterClassExandRegisterClipboardFormat. AtomBombing technique uses this structure as a medium for delivering the payload; combined with APCs and ROP, it provides access to code injection.
"Backdoor"-like Injections
So far, we distinguished injectors based on how they gain execution and deliver the code or data. There is also a set of techniques that do not fall into these categories because they, effectively, don't use most of the facilities we've seen so far. The mechanisms we discuss in this section were introduced by Microsoft and implemented accordingly, i.e., by extending the functionality of system libraries. When specific conditions are met, they will automatically load and invoke user-controlled DLLs on the target's behalf. There are similarities of this behavior with backdoors, hence, the name.
The most widely used technique in this category is SetWindowsHookEx. This API adds support for installing a wide range of window message processing-relates hooks on both global and a per-thread scale. While some of them allow receiving notifications about specific events (such as key presses) on the calling thread, a few must execute within the context of the target process and, thus, require a DLL to perform the actual work. Whenever a window in the scope of the hook receives a specific window message, the system automatically forces its owning thread to load our DLL. Despite the simplicity, there are two moderately significant limitations to this technique. Firstly, the function works only against applications that include GUI threads, preferably actively pumping messages. Secondly and more importantly, it is not suitable for typical DLLs. To work, the library either needs to contain a specifically designed callback function or perform all tasks in DllMain and then always fail the loading. Because of these limitations and the detailed documentation provided by Microsoft, we are not providing a demo project for this technique in the repository.
If injecting a DLL on process startup is also a viable option, here are a few facilities that can help:
- AppInit_DLLs. AppInit_DLLs is a registry key under HKLM that defines a list of libraries that user32.dll - a core library for any UI-related functionality - will automatically load during its initialization. Because of the system-wide scope, this technique is more suitable for persistence rather than targeted injection. Besides that, AppInit_DLLs were deprecated and are now disabled by default. Even when enabled, they might be configured to require digital signing.
- AppCompat shims. This infrastructure provides an extensible mechanism for applying compatibility fixes for legacy applications. Shims target specific executable files that they recognize based on various properties. Custom shim providers can bring DLL dependencies and get them loaded in the early stages of process initialization. Microsoft EMET used this approach to load its library and apply additional mitigation policies to programs running on older versions of Windows. Keep in mind that installing new shims requires creating and registering a *.SDB (shim database) file and generally requires administrative permissions.
- Custom Application Verifier providers. These libraries act as plugins for Application Verifier - a built-in OS component and a framework for testing the application's stability and compatibility. They also get loaded early during process initialization but, unfortunately, require administrative permissions to register.
Manual DLL Mapping
The final approach we will discuss here is truly marvelous because it goes an extra mile to extend the functionality of DLL loading and significantly improves its resilience to detection. Welcome manual mappers - techniques that re-implement LoadLibrary from scratch.
There are two primary reasons to bother with this approach. Firstly, LoadLibrary is a common denominator for all other DLL injectors. Consequently, it is heavily monitored by security software. The underlying LdrLoadDll is in a better position from the attacker's perspective, but just slightly. Secondly, these functions expect a filename as their input, limiting their use only to filesystem content. As we will see below, manual mapping doesn't have this limitation and supports loading DLLs from memory.
How Does DLL Loading Work?
Module loader is implemented in user mode in ntdll.dll - the Native subsystem library that is always loaded into all processes. Here is the list of the most essential steps it takes to load a DLL:
- Open the file via
NtOpenFilefor the Read & Execute access. - Create an image section (memory mapping) object via
NtCreateSectionwith theSEC_IMAGEattribute from the file. This step makes the system read the file and validate its structure according to the PE specification. In some cases, the kernel might also apply image relocations (discussed below) at this step. - Map the image section object via
NtMapViewOfSection. The new memory region will provide a copy-on-write view on the DLL but with a slightly different (so-called image) layout. Each PE section will get the specified memory protection (R/RW/RX/etc.) set automatically. - If necessary, apply relocations in user mode. PE files (both .exe and .dll) are rarely entirely position-independent; instead, they have a preferred image base address (specified in the headers). Whenever the file gets mapped at a different location (either because of mandatory ASLR or already occupied memory), the loader must apply some patches to the memory content.
- Resolve imports and recursively load dependencies. Executable files define dependencies via the use of the import table; it becomes the responsibility of the loader to locate necessary functions in the export directory of referenced libraries and bind them together.
- Invoke the library's TLS initialization callbacks and the entry point upon successful loading.
There are, of course, a lot of other implementation details that we won't cover, but these are less relevant to our goals. They include, for example, support for KnownDlls and the structure of the lists where the loader maintains the database of modules.
Can We Do The Same?
Most importantly, because the module loader is implemented in user mode and, therefore, follows the same rules of interaction with the kernel, it is possible to closely reproduce its behavior. Ultimately, we can even include a few improvements. As long as we deploy the image following the same layout and memory protection and then resolve its imports, relatively simple code should work correctly. Of course, the more complex the DLL gets, the more precisely we need to reproduce the loader's behavior.
There are three approaches we can take for reproducing the memory layout of a loaded DLL:
- Allocate private
MEM_COMMITmemory and then fill it in remotely via cross-process writing. Finally, set the necessary memory protection afterward. - Map shared
SEC_COMMITmemory. The primary benefit of this approach is that we can map a local view of this region first, deploy the image there (write it, apply relocations, resolve imports, etc.) and only then map a ready-to-run remote view. - Map a shared
SEC_IMAGEview of the image. This approach is whatLoadLibrarydoes under the hood. It automatically fixes PE section layout and protection and often even relocations. Unfortunately, it requires a file on the disk. Additionally, it notifies kernel-mode drivers about image loading, making it less suitable for stealthy injectors.
Probably the most widely known implementation of manual mapping is called reflective loading. This technique either relies on injecting a shellcode that allocates and deploys the image from an in-memory buffer and then invokes its entry point or requires a specially crafted DLL. All implementations of reflective loading we've seen are based on the first option from our list (private MEM_COMMIT memory) and perform most tasks inside the target process. These design choices simplify some tasks such as resolving imports but might lead to drawing suspicion of the security software and lead to detection.
Since the primary topic of this discussion is the inter-process injection, the demo project for manual mapping included in this repository performs as many steps as possible remotely. It also relies on the second option (shared SEC_COMMIT memory) because of its benefits for image deployment. Comparing the implementation to reflective loading, we can highlight that there are merely a few steps that touch the target process:
- Enumerating loaded modules while resolving imports. This action repeatedly queries the target's address space but doesn't require reading any memory.
- Mapping a region with the prepared content and layout using the RWX/WCX protection.
- Optionally applying more restrictive memory protection to specific pages.
- Creating a new thread and queueing an APC to execute the module's DllMain.
Conclusion on Code Injection
The categorization we introduced should cover the reasonable majority of DLL (and, partially, shellcode) injection techniques and their variations, probably even the future ones. Of course, the landscape constantly changes as it has been for years, thanks to the work of many dedicated security researchers. Detection methods also competitively evolve over time (as you can read in the corresponding writeup), so keeping the arsenal of tricks in your sleeve up-to-date is essential. Still, we believe that the material provided here can provide valuable insight on the topic, both for beginners and professionals.
Detection
The techniques for concealing code execution that we discussed in the offensive ([1], [2]) parts of the project have a shared primary objective: they are designed to fool security software and bypass security policies. Identifying something that actively hides its presence can prove challenging because of the inherent limitations it imposes on the detection methods. Luckily for defenders, most evasion techniques share common flaws that allow hunting for their entire families. Just keep in mind that the traces they leave on the system are often overlooked by antiviruses and might require using custom tooling.
Here is a high-level overview of the topics covered in this write-up:
- Static detection
- Runtime detection
- Forensic detection
Static Detection
Signature-based detection provides a decent starting point because it can recognize known malware and its variations by looking for shared patterns. The primary advantage of using this approach is that the analysis can be performed before execution and, thus, is suitable for providing the first echelon of defense. Of course, signature-based detection works best against well-known samples. Attempting to classify uncommon, re-compiled, or obfuscated programs, on the other hand, often yields inconsistent results that heavily depend on various parameters. Because of that, false negatives might still allow malicious programs to stay under the radar, while false positives become a source of constant frustration among writers of system tools. That being said, now we can focus on discussing the most fundamental property of the tools for purposefully concealing code execution: the API dependencies.
Hiding malicious code inside a process that belongs to (or appears to belong to) a trusted component inevitably requires the help of the underlying operating system. The OS effectively owns all resources that programs use for anything more than purely algorithmic computations, so malicious (as well as any other) code needs to use the services it provides to work with such resources.
The scope of this research includes two classes of techniques, both of which primarily operate on two types of securable objects: processes and threads. To start with, let's focus on the first class of techniques - shellcode and DLL injection. As described in more detail in the corresponding write-up, code injection almost always includes two phases: delivery and execution. Additionally, it might also include some reconnaissance logic to identify a suitable target for injection. Here is an overview of the API calls that are typically used in each stage:
| API | Category | Usage |
|---|---|---|
| EnumProcesses / CreateToolhelp32Snapshot / NtQuerySystemInformation | System | Enumerating processes on the system to find a suitable target for injection. |
| OpenProcess / NtOpenProcess | Processes | Gaining access to the target process to perform subsequent manipulations. |
| VirtualAllocEx / VirtualAlloc2 / NtAllocateVirtualMemory | Memory | Allocating memory in the specified process. |
| WriteProcessMemory / NtWriteVirtualMemory | Memory | Writing shellcode or DLL filename into an address space of another process. |
| VirtualProtectEx / NtProtectVirtualMemory | Memory | Making a memory region in another process writable or executable. |
| OpenThread / NtOpenThread | Threads | Accessing a thread in another process to gain execution. |
| CreateRemoteThread / CreateRemoteThreadEx / RtlCreateUserThread / NtCreateThreadEx | Threads | Invoking code in another process. |
| QueueUserAPC / QueueUserAPC2 / NtQueueApcThread / NtQueueApcThreadEx / RtlQueueApcWow64Thread | Threads | Gaining execution on an existing thread in a different process via Asynchronous Procedure Calls |
| SetThreadContext / NtSetContextThread | Threads | Directly hijacking execution of a thread by manipulating its registers. |
The second class of techniques we cover in this repository focuses on concealing code on a scale of an entire process. Because it's substantially easier to tamper with processes that haven't started execution, such techniques almost always launch them in a suspended state. Additionally, most stealthy Process Tampering techniques rely on a highly specific and extremely low-level (thus, irreplaceable) functions. The reason for that is currently irrelevant (it is explained in great detail in the corresponding write-up); what is essential is that these functions can serve as a reliable indicator for detection purposes. As for the rest, the list of commonly used API calls overlaps with the one shown earlier. Although, this one has a more noticeable focus on memory operations due to the nature of low-level process creation.
| API | Category | Usage |
|---|---|---|
| NtCreateProcess / NtCreateProcessEx | Processes | Creating a new process from a memory mapping instead of a file. |
| CreateRemoteThread / CreateRemoteThreadEx / RtlCreateUserThread / NtCreateThreadEx | Threads | Creating the initial thread in the target process. |
| SetThreadContext / NtSetContextThread | Threads | Adjusting the start address of the initial thread. |
| ResumeThread / NtResumeThread / NtResumeProcess | Threads | Resuming target's execution after tampering. |
| CreateFileMapping / CreateFileMapping2 / NtCreateSection / NtCreateSectionEx | Memory | Creating a memory mapping object to project an executable file into the address space of the target process. |
| UnmapViewOfFile2 / NtUnmapViewOfSection / NtUnmapViewOfSectionEx | Memory | Unmapping the original executable from the address space of the target process. |
| ReadProcessMemory / NtReadVirtualMemory | Memory | Reading the image base address from a remote Process Environment Block (PEB). |
| VirtualAllocEx / VirtualAlloc2 / NtAllocateVirtualMemory | Memory | Allocating remote memory for the process parameters block. |
| WriteProcessMemory / NtWriteVirtualMemory | Memory | Filling in the process parameters and adjusting pointers in PEB. |
| CreateTransaction / NtCreateTransaction | Other | Creating a filesystem transaction for temporarily replacing the file (see Process Doppelganging). |
To help automate the static detection of suspicious executables, we include a set of YARA rules that look for the use of API functions described above. Note that these rules target an entire family of techniques rather than specific samples. Therefore, they are meant to be used as an indicator of suspiciousness rather than maliciousness.
Runtime Detection
Runtime detection allows automatically analyzing the behavior of software as it runs and provides a convenient layer of defense against programs that abuse misconfigurations in security policies and weaknesses of security mechanisms. Runtime detection logic can operate in two distinct modes:
-
Synchronous mode. Security products that synchronously collect data about a program's attempts to perform sensitive operations have a notable advantage: they can work as a host-level intrusion prevention system. By definition, the operating system forces processes (malicious or not) to wait until the anti-malware services verify and acknowledge such operations. Because of that, the developers of detection engines don't need to worry about being too late to take action. They can apply behavioral analysis and heuristic rules and even make reputation-based decisions on a per-operation basis. As a downside, though, synchronous detection can introduce noticeable performance degradation when used excessively, forcing the vendors to minimize the scope and the amount of detection logic.
-
Asynchronous mode. These lightweight detection mechanisms subscribe to various notifications or perform constant pulling (for example, by reading the recent logs), observing events after they happen. Because these are non-blocking operations, the security software might get notified with a noticeable delay, which yields asynchronous detection useless for active prevention. On the upside, the operating system generates plenty of rich telemetry data that can be valuable for performing detailed analysis and can be consumed without the complications typical for the synchronous mode. Additionally, a portion of the changes observable in the asynchronous mode is also available for post-factum forensic analysis.
Before we start describing the specifics, let's take a closer look at a typical example of DLL injection and the operations that we can expose it:

As you can see, code injection relies on performing rather noisy actions and provides multiple triggers suitable for detecting and blocking it. However, reliable synchronous detection mechanisms require support from the underlying operating system, so not all these operations are equally easily observable.
Windows provides several callbacks available from the kernel that are especially useful for revealing concealed code execution.
- Process creation and termination callbacks. These callbacks are extremely useful under various conditions but come with a few intricate caveats. As discussed in more detail in the dedicated write-up, Windows notifies drivers about process creation when it inserts the initial thread into the new process and not when it creates the object. Multiple Process Tampering techniques exploit this window of opportunity to introduce a mismatch that hides the code.
- Thread creation callbacks. Generally, security software is not interested in intercepting thread creation within a process because of the volume of events and little value they bring. One notable exception is cross-process thread creation. While it does have legitimate purposes (such as debugging), it also became one of the favorite mechanisms for gaining execution during shellcode and DLL injection due to its simplicity.
- Image loading and unloading events. DLL loading is an operation built on top of the operating system's ability to project (or map) executable files into memory. Despite generating a substantial amount of events (one per every use of this functionality) that might introduce performance bottlenecks, this event alone allows to catch most DLL injection techniques. Unfortunately, it might be tricky to determine whether the load operation originated from the process's legitimate dependency on a specific library or an injection attempt. Also, an advanced class of techniques exists called manual mapping that relies on alternative means for loading executable code into memory that doesn't trigger this event.
- Process open operation callbacks. Most injection techniques require a delivery step that copies the shellcode or a DLL filename into the target process's address space. Processes are securable objects, so unless this delivery step uses a pre-existing shared memory region (which is possible in some cases), the attacker needs to open a handle to the target process. There can be many reasons for a program to interact with other processes on the system, yet, only a few require requesting access for creating remote threads or performing remote memory operations.
- Thread open operation callbacks. Opening threads in other processes is a less common operation that still allows gaining code execution. The most widely known examples of techniques that rely on it are thread hijacking and APC queueing.
When combined, these core mechanisms can form a formidable line of defense. That's why most modern security products already subscribe (or at the very least should subscribe) to these events and use them to block known malware samples. If you're not planning to write your kernel driver for synchronous detection, perhaps, the most convenient option is to use Sysmon. It exposes easily-consumable events from the first four callbacks and logs a substantial amount of data that can help to correlate them. It also covers some file-system operations (which we haven't discussed) that might come in handy for detecting malware that drops files on the disk.
If you compare the list of operations described in the diagram, you'll notice that kernel callbacks don't cover the entire spectrum of what we might want to detect in the synchronous mode. For example, Windows doesn't include built-in facilities for intercepting remote memory allocation and modification. In such cases, the common choice of security software is to rely on a fallback interception mechanism - user-mode hooks. Typically, an AV/EDR system uses its privileged position to globally inject a library that patches the first instructions of the functions of interest and intercepts their execution. The library then forwards the passed parameters to the detection logic, which logs the operation and determines whether it should be allowed. It's essential to understand the limitations of this approach as it does not provide security guarantees because it relies on the program's willingness to tolerate hooks. Software is generally allowed to do whatever it wants with its memory and the instructions in this memory, including patching it back to the original state.
Finally, if we merely want to monitor the system for suspicious activity in an asynchronous mode, Windows provides support for security auditing. The current version includes as many as 59 different categories of events, although not as many are helpful for our purposes. It can detect privilege use, handle manipulation, and in some cases, even help detect advanced techniques like Process Doppelganging. Another example is if you carefully configure SACLs (System Access Control Lists) on a per-directory basis to audit FILE_EXECUTE access, Windows Auditing can generate events on DLL loading from user-writable locations. You can also achieve similar results by deploying AppLocker rules and Windows Defender Application Control code integrity policies.
Forensic Detection
Whenever the previous stages of detection fail, it becomes essential to understand how and when the exploitation happened so we can improve our defenses. That's where forensic investigations come into play. Code injection is hardly an operation that leaves no traces; it's just a matter of knowing where to look. There are two main approaches for performing such detection:
- Memory dump-based forensic detection. In this approach, we can inspect the memory of the target process and, sometimes, the OS kernel; yet, we cannot perform other operations such as issuing API calls to querying additional information. The primary objective, thus, becomes scanning the memory for the presence of anomalies and indicators of compromise. In the case of code injection, we typically look for executable memory that doesn't belong to any of the legitimate libraries we expect to find in the target process. It might take the form of a private memory region with just assembly instructions, a dynamically loaded 3-rd party library, or some combination of both.
- Live forensic detection. In this scenario, we have access to (typically administrative-level) code execution on the machine, so we can effectively perform everything that memory dump-based forensics can, plus interact with the working operating system. As a result, we have more information sources and, therefore, can perform a much more complete analysis. For example, we can query the memory manager for additional information, use working set watches, observe how stack traces change over time, and potentially even debug the target process using instruction and data breakpoints.
Loaded Modules & Mapped Images
The diagram from the runtime detection section mentions several visible traces that DLL injection leaves in the target's process memory. These traces include the executable memory region coming from the DLL itself, plus some other internal data structures used by the module loader to identify this region. Whenever a process loads a file using LoadLibrary (or the underlying LdrLoadDll), the system adds an entry into the loader database. Later we can parse these structures and extract various valuable information, including:
- The full path used at the time of loading. Because filenames can take multiple forms (UNC, normalized, DOS 8.3, with intermediate directory junctions, etc.), knowing the original string might shed some light on the operation that caused loading.
- The load reason, such as static, dynamic, forwarder, or delayed.
- The timestamp when the loading took place.
- The timestamp from the PE file header.
- The base address of the DLL and its size.
Finally, knowing the address, we can query the memory manager and retrieve the current path to the file. The system keeps track of rename operations on mapped images so the output can be more accurate than the one stored in the loader database. If the file was additionally tampered with (such as being deleted or overwritten in a transaction), the query fails, but the error code still provides valuable insight on the reason.
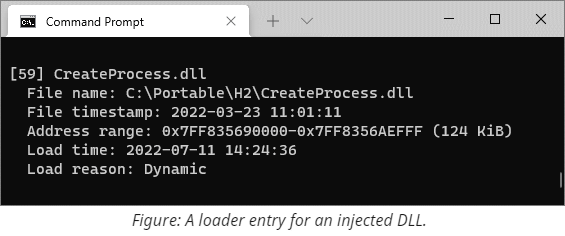
There are several GUI tools that allow inspecting this information, most notably System Informer (formerly known as Process Hacker). Here you can see a screenshot of how two views (memory vs. loader data) accompany each other:

In case you are limited to command-line tools only or need to operate on memory dumps, we include two simple programs with similar functionality. LoadedModules provides a flat view of the loader database, while MappedImages iterates over memory and retrieves current filenames for images. Both tools can operate on live systems or capture minidumps and then inspect them in offline mode.
Of course, recognizing more sophisticated attacks that map executables manually or patch memory that belongs to legitimately loaded modules requires more insight than these small tools included with the repository can provide. The primary focus during hunting for such attacks shifts towards searching for anomalies throughout the entire view of memory. Here is a list of commonly established indicators of compromise that should draw attention and subsequent investigation:
- Executable memory that does not belong to mapped images. Many code (and, especially, shellcode) injection techniques allocate private memory regions to host machine instructions without writing them to the disk. A less common but still valid approach is to use shared mapped memory. Either way, unless we expect the target process to use just-in-time compilation, all of its executable memory should be backed by mapped image files.
- Mapped images without corresponding entries in the loader database. The idea behind this detection is simple: if defenders want to see code only inside mapped images, attackers can still make it happen without going through the normal process of loading DLLs. This item covers scenarios when an attacker manually creates and maps a section object. Performing these operations manually (as opposed to delegating them to the OS) opens more possibilities for tampering and might be worth investigating.
- Executable memory within mapped images that became private due to modification. By default, mapping executables into memory is very space-efficient because Windows shares all non-writable pages. If somebody changes protection and modifies such pages, the system allocates and switches to a process-private copy. This transition from shared to private is detectable and remains this way even after reverting the protection to its original value. The open-source memory analysis tool Moneta relies on this behavior for recognizing a wide range of code injection scenarios.
- Patched executable memory. Finally, the most verbose and expensive option is to check whether all loaded modules contain the exact bytes in the executable regions as they are supposed to. The scanner, therefore, needs to open every mapped PE file, parse its structures, apply relocations, and compare bytes from each executable section. System Informer (formerly known as Process Hacker) exposes this feature under the Image Coherency column and outputs the percentage of resemblance between the file on disk and its projection in memory. Another open-source tool called PE-sieve performs a similar comparison but additionally provides support for dumping and reconstructing modified images from memory back to files for subsequent analysis.
Unloaded Modules
Combining all memory forensics tricks described above provides a formidable solution for detecting side-loaded code. These techniques, however, rely on an unspoken assumption that the payload is still present at the time of the investigation. Yet, we might be interested in unwinding the clock and exploring previously loaded code. It is, of course, impossible to reconstruct memory content (and even just its layout) at a specific point in the past in the general case without prior preparations. Nevertheless, it is possible to extract some traces of DLLs long after unloading.
More specifically, the image loader from ntdll keeps track of the last 64 DLL unload events, recording filenames, address ranges, timestamps, and a few other fields. This trace is stored in the target's process memory and is accessible via RtlGetUnloadEventTraceEx.

The UnloadedModules tool from this repository can parse and display such traces from live processes and minidumps, plus capture minidumps for later analysis.
Process Identity
The discussion so far focused on code injection, and while most of the suggestions still apply when detecting process tampering, there are also a few differences worth mentioning. First, as opposed to the DLL loading procedure, the user-mode image loader doesn't load the main executable - it only resolves its imports and records information about what's already there. Therefore, it fully trusts the image name string that the creator provides in the parameters block. Secondly, the system supports creating processes in a suspended state, which introduces an artificial delay and constitutes the primary period for performing tampering. Finally, Windows records more information about the process and the main module than about subsequently loaded DLLs. Identifying contradictions between the fields that come from different sources but should otherwise contain identical information proves crucial for successful detection.
Here is an overview of the fields and properties of interest:
- The short image name that appears in the process snapshots. The system populates this field from the executable's name during process object creation. The value becomes an empty string if the name cannot be retrieved, for example, when the file has already been deleted. The value doesn't track subsequent renames.
- The Win32 path to the executable accessible via
NtQueryInformationProcesswithProcessImageFileNameWin32. The system dynamically retrieves this string from the file used to create the process. Thus, it tracks rename operations. The query results in an error if the file doesn't have a valid Win32 name or has been deleted. - The Native path to the executable accessible via
NtQueryInformationProcesswithProcessImageFileName. The system populates this string by looking up the name from the file object during process creation and doesn't track subsequent renames. The field holds a null pointer if the system fails to retrieve the value. - The ImagePathName field from the
RTL_USER_PROCESS_PARAMETERSstructure stored in user-mode memory. The process's creator explicitly provides this string on the Native API level and has complete control over its value. - The FullDllName and BaseDllName fields of
LDR_DATA_TABLE_ENTRYfor the main module from Process Environment Block. Once the process starts, the code from ntdll copies the string fromImagePathName(see the previous item) into the loader database. Because this string also resides in user-mode memory, it can be easily modified even after process initialization. - The first portion of the command line. This string is also explicitly provided by the creator of the process. Aside from reading it directly from
RTL_USER_PROCESS_PARAMETERS, other components can useNtQueryInformationProcesswithProcessCommandLineInformation, which reads the string from user-mode memory, and, thus, reflects any changes made there. - The Native filename of the section object mapped at the image base address. This string can be retrieved using
NtQueryVirtualMemorywithMemoryMappedFilenameInformation, which looks up the current path to the file and tracks renames. If the provided address belongs to private memory or the filename cannot be determined, the query fails.
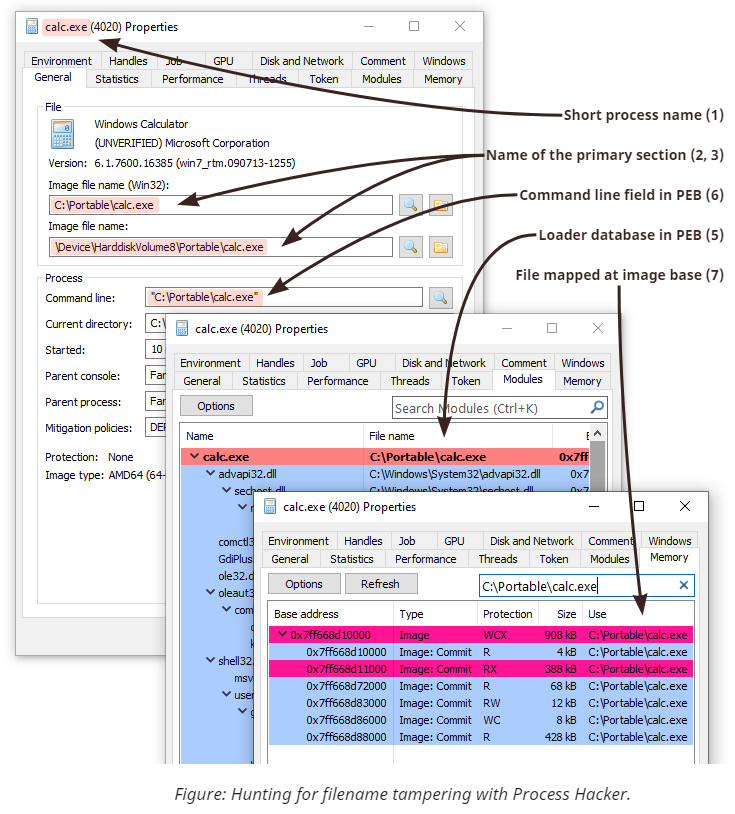
Aside from the strings, there are also two important pointer values:
- The image base address. This value is stored in
PEB(Process Environment Block) and gets chosen automatically during process creation. Because PEB resides in user-mode memory, this field is easy to overwrite to point to a new location. Ntdll uses this value internally during process initialization and copies it into the loader database. - The start address of the initial thread. This value appears in one of the registers (rcx, eax, R0, or X0, depending on the platform) of the first thread before it starts. When using
NtCreateUserProcess-based techniques, the system sets the value to the entry point of the main executable per the chosen image base. Some tampering techniques need to modify the start address to redirect execution. Creating a process withNtCreateProcessExrequires the caller to provide the values when manually creating the initial thread. Note that ntdll infers the value for the entry point field to store in the loader database independently based on the image base and the PE headers.
As mentioned earlier, revealing a mismatch between various properties is crucial for identifying process tampering. Here, the details matter because even error codes provide valuable insight into the nature of the subject.

On the screenshot above, you can see how the ProcessIdentity tool allows us to distinguish several most common process tampering techniques solely based on comparing a few properties that would otherwise be identical.
Conclusion on Detection
While modern techniques for concealing code execution might fool security software that relies on more naïve classical approaches for scanning, it's not by any means impossible to catch given appropriate attention. We hope that this paper shares the necessary knowledge and tools to make the world more secure by combating the favorite techniques of Advanced Persistent Threat actors.
Further Reading
Here you can find more quality material from other authors on the topic:
- Process Herpaderping paper by Johnny Shaw.
- Lost in Transaction: Process Doppelgänging - the original slides from Black Hat 2017 by Tal Liberman and Eugene Kogan.
- Masking Malicious Memory Artifacts by Forrest Orr. See also parts two and three of the series.
- Using process creation properties to catch evasion techniques by Microsoft 365 Defender Research Team.
- Process Doppelgänging meets Process Hollowing in Osiris dropper - analysis by Malwarebytes Labs.